스파르타코딩클럽의 강의를 참고하여 정리하였습니다
회귀분석(regression analysis)
관찰된 연속형 변수들에 대해 두 변수 사이의 모형을 구한 뒤 적합도를 측정해 내는 분석 방법 (wikipedia)
선형회귀
1. 단순회귀분석(simple regression analysis) : 하나의 종속변수(Y)와 하나의 독립변수(X) 사이의 관계를 분석할 경우
2. 다중회귀분석(multiple regression analysis) : 하나의 종속변수와 여러 독립변수 사이의 관계를 규정함
선형회귀(Linear Regression)
종속변수Y와 한개 이상의 독립변수X와의 선형 상관관계를 모델링 하는 회귀분석
선형 예측 함수를 사용해 회귀식을 모델링하며, 알려지지 않은 파라미터는 데이터로부터 추정한다 -> 선형모델
- 값을 예측하는 것이 목적일 경우, 선형 회귀를 사용해 데이터에 적합한 예측 모형을 개발한다. 개발한 선형 회귀식을 사용해 y가 없는 x값에 대해 y를 예측하기 위해 사용할 수 있다.
- 종속 변수 y와 이것과 연관된 독립 변수 X1, ..., Xp가 존재하는 경우에, 선형 회귀 분석을 사용해 Xj와 y의 관계를 정량화할 수 있다. Xj는 y와 전혀 관계가 없을 수도 있고, 추가적인 정보를 제공하는 변수일 수도 있다.
선형회귀 평가지표
1. 회귀(숫자를 맞추는 방법): MES (Mean Squared Erorr)-> 평균 제곱 오차
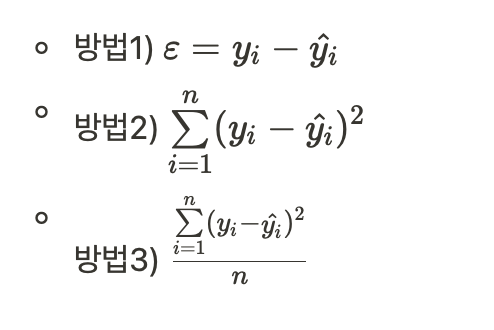
- 방법1) 에러 = 실제 데이터 - 예측 데이터 로 정의하기
- 방법2) 에러를 제곱하여 모두 양수로 만들기, 다 합치기
- 방법3) 데이터만큼 나누기
- 목표: MES의 최소화 -> 에러를 최소화 시키는 것
- RMSE: MSE에 Root를 씌워 제곱 된 단위를 다시 맞추기
2. R-Square: 전체 모형에서 회귀선으로 설명할 수 있는 정도 (평균값보다 예측을 잘 했겠지?)

- 의미: 평균에서 실제데이터의 차이는 평균에서 회귀선(예측값)의 차이와 회귀선(예측값)과 실제값의 차이의 합 -> 회귀 모델에서 독립변수가 종속변수를 얼마만큼 설명해 주는지 가리키는 지
- 목표:0~1 , 높을 수록 잘 설명함
- 계산: (예측값-평균값) / (실제값-평균값)

회귀분석의 적합도
잔차검정 -> 정규성과 등분산성 만족에 대한 검토
연습 1. 몸무게와 키의 상관관계 찾기
1. 라이브러리 설치
import sklearn
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
- 데이터 불러오기
weights = [87, 81, 82, 92, 90, 61, 86, 66, 69, 69]
heights = [187, 174, 179, 192, 188, 160, 179, 168, 168, 174]
print(len(weights)) #데이터 길이확인
print(len(heights)) #데이터 길이확인
- 딕셔너리 형태로 데이터프레임 생성 by pandas
body_df = pd.DataFrame({'height' : heights, 'weight' : weights})
body_df.head(3)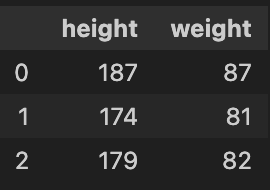
2. 산점도 그리기 by seaborn
#weight와 height간의 산점도(scatter plot)
sns.scatterplot( data = body_df, x = 'weight', y = 'height')
plt.title('Weight vs Height')
plt.xlabel('weight(kg)')
plt.ylabel('Height (cm)')
plt.show()
3. 선형회귀 모델 불러오고 훈련하기
# 선형회귀 훈련(적합)
from sklearn.linear_model import LinearRegression # 선형모델을 클레스에서 가져와서
model_lr = LinearRegression() #클래스를 변수에 저장
type(model_lr)-> 타입: sklearn.linear_model._base.LinearRegression
💡sklearn: Scikit-learn이라고 부르며 가장 많이 사용되는 머신러닝
1) 알고리즘: 분류(classification): iris -> 구현을 위한 클래스: Classifier
2) 알고리즘: 회귀(regression) -> 구현을 위한 클래스: Regressor
등등
(1) 메서드 fit() -> 모델학습
(2) 메서드 predict() -> 결과예측
등등

# DataFrame[]: Series(데이터 프레임의 컬럼)
# DataFrame[[]]: DataFrame
X = body_df[['weight']]
y = body_df[['height']]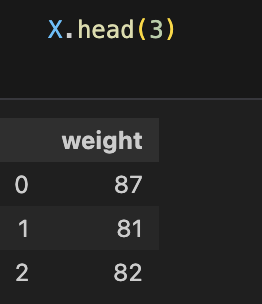 |
 |
#데이터 훈련
model_lr.fit(X = X, y = y)
# 가중치(w1)
print(model_lr.coef_)
# 편향(bias, w0)
print(model_lr.intercept_)[[0.86251245]]
[109.36527488]
w1 = model_lr.coef_[0][0] -> 2차원 구조
w0 = model_lr.intercept_[0] -> 1차원구조
print('y = {}x + {}'.format(w1.round(2),w0.round(2)))
#y = 0.86x + 109.37
즉, y(height)는 x(몸무게)에 0.86을 곱한뒤 109.37을 더하면 된다.
4. 평가: MES, Z-Score
4-1) MES 수식을 통해 계산하기
선형함수를 활용하여 예측값과 에러값(실제-예측)계산 후 에러값을 제곱하여 모두 더하고 데이터수량으로 나누기
4-1-1) 예측값을 통해 에러값 계산하기
#예측값을 만들기
body_df['pred'] = body_df['weight']*w1 + w0 #w1:가중치 w1:편향
body_df.head(3)# 에러
body_df['error'] = body_df['height'] - body_df['pred']
body_df.head(3)
4-1-2) MES 계산하기
#제곱하여 에러를 양수로 만들어 주기
body_df['error^2'] = body_df['error']*body_df['error']
# MSE계산 완료 : 제곱한 에러의 합을 데이터수량으로 나눔
body_df['error^2'].sum()/len(body_df)>> 10.152939045376318
💡 선형그래프 그리기
sns.scatterplot(data = body_df, x = 'weight', y = 'height')
sns.lineplot(data = body_df, x = 'weight', y = 'pred', color = 'red')
4-2) 함수를 통해 계산하기
from sklearn.metrics import mean_squared_error
from sklearn.metrics import r2_score
# 동일 from sklearn.metrics import mean_squared_error, r2_score
4-2-1) MES계산
# 평가함수는 공통적으로 정답(실제 true), 예측값(pred)
y_true = body_df['height']
y_pred = body_df['pred']
mean_squared_error(y_true, y_pred)
>> 10.152939045376318
4-2-2) Z-score 계산
r2_score(y_true, y_pred)>> 0.8899887415172141
4-2-3) 예측값 계산하기
y_pred2 = model_lr.predict(body_df[['weight']])
y_pred2
4-2-3) 함수를 통해 예측한 값의 에러값
mean_squared_error(y_true,y_pred2)
>> 10.152939045376318

https://dacon.io/codeshare/4421
sklearn으로 파이썬 머신러닝 입문하기🔥 - 분류 모델
dacon.io
'학습노트 > Python' 카테고리의 다른 글
| [강의노트] Python - 머신러닝 - 선형회귀-실습(2) (1) | 2024.01.30 |
|---|---|
| [강의노트] Python - 머신러닝 - 선형회귀-실습(1) (2) | 2024.01.30 |
| [강의노트] Python - 데이터전처리: Pandas(3) - 실습 (0) | 2024.01.25 |
| [강의노트] Python - 데이터전처리: pandas(1) (1) | 2024.01.23 |
| [강의노트] Python - Pandas, matplotlib 활용1 (1) | 2024.01.17 |



