스파르타코딩클럽의 강의를 참고하여 정리하였습니다
1. pandas 불러오기
import pandas as pd
import seaborn as sns
2-1. 데이터불러오기
seaborn에 있는 오픈 데이터 불러오기
data= sns.load_dataset('tips')
2-2. 데이터 저장하기 -> 현재위치에 저장
기능: 나중에 데이터 전처리가 끝나고 데이터 저장 가능
#현재위치(파일)에 파일 저장
data.to_csv("tips_data.csv")
#파일을 지정하여 저장하고 싶을 때 "피일명/데이터.확장자"
data.to_csv("temp/tips_data.csv")
#인덱스 없이 저장하고 싶을 때
data.to_csv("tips_data.csv", index=False)
#인덱스 없이 불러오고 싶을 때
df=pd.read_csv('/Users/t2023-m0017/Desktop/통계실습/tips_data.csv',index_col=0)index생략 또는 index=True의 경우 자동으로 인덱스 생설

💡 엑셀파일로 저장하고 싶을 때
data.to_excel("temp/tips_data.xlsx")
저장이 안될 경우: 터미널 > pip install openpyxl
3-1. 데이터프레임과 인덱스
참고: https://jimmy-ai.tistory.com/155
[Pandas] 파이썬 인덱스 설정 방법 정리(set_index 함수)
판다스 set_index 함수 사용법(데이터프레임 인덱스 지정) 안녕하세요. 이번 시간에는 파이썬 판다스 라이브러리에서 데이터프레임의 인덱스를 지정할 수 있는 set_index 함수의 경우의 수에 대하여
jimmy-ai.tistory.com
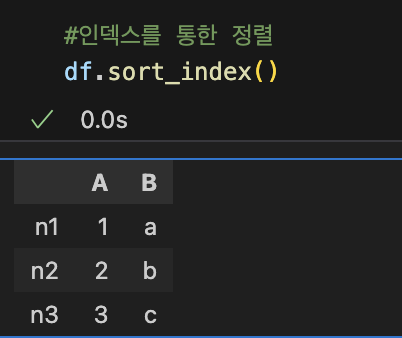
#인덱스 지정 X
df=pd.DataFrame({
'A': [1,2,3],
'B': ['a','b','c']
})
#인덱스 지정
df=pd.DataFrame({
'A': [1,2,3],
'B': ['a','b','c']
}, index=['n1','n2','n3'])| 인덱스 지졍x, 기본인덱스 | 인덱스 지정 |
 |
 |
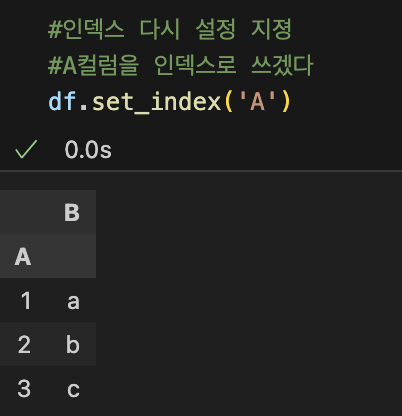
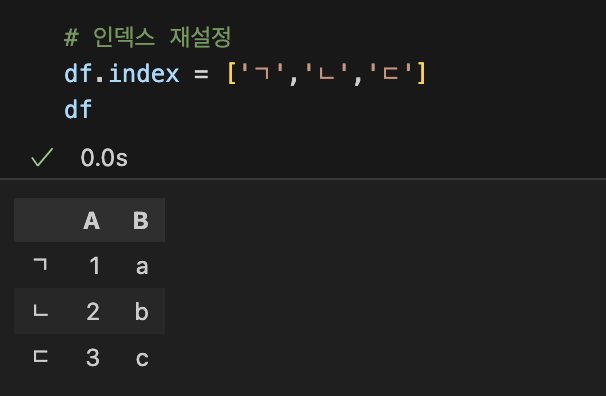
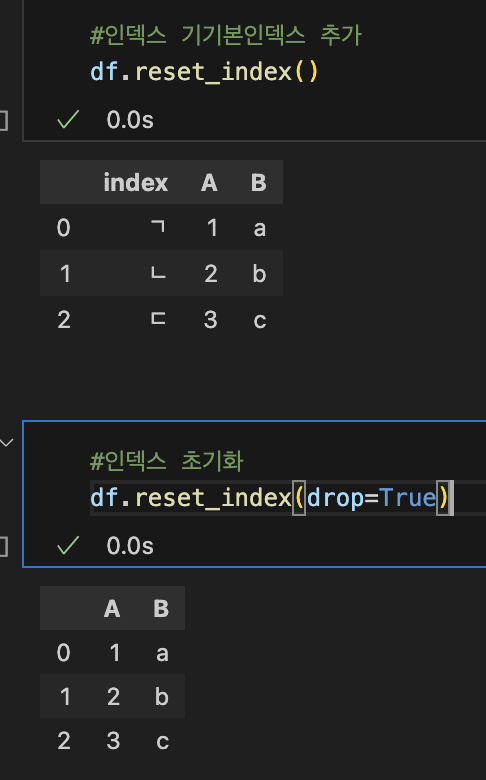
3-2. 인덱스 관련 함수들
 |
 |
 |
 |
 |
 |
3-3. 데이터 프레임과 컬럼(열 또는 변수)
data= {
'name' : ['Alice','Bob','Charlie'],
'age' : [23,30,40],
'gender' : ['female','male','female']
}
df= pd.DataFrame(data)
df컬럼: name, age, gender
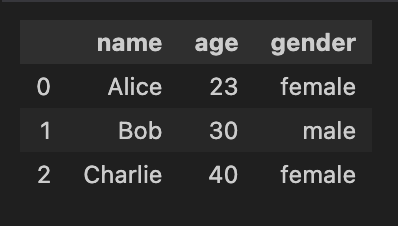
| 해당컬럼의 데이터 보기 | 데이터프레임의 컬럼보기 | 컬럼이름 바꾸기 |
 |
 |
 |
| 컬럼의 이름 바꾸기 | 컬럼추가하기 | 컬럼 지우기 |
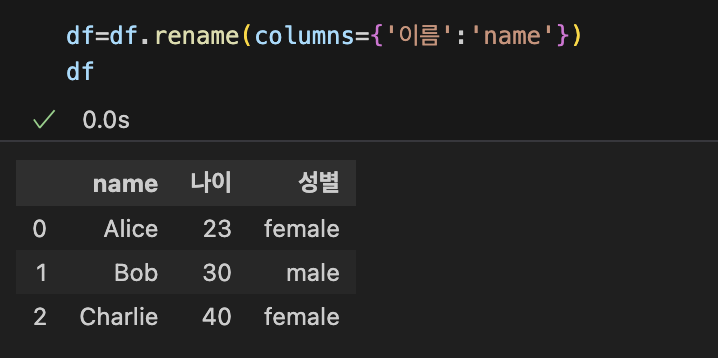 |
 |
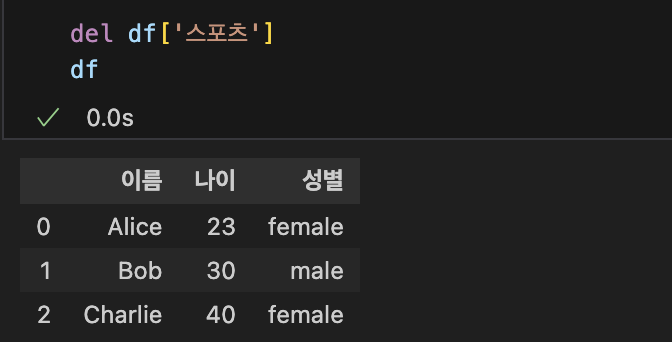 |
4. 데이터 확인하기
4-1. 데이터 요약 head(), info(), describe()
| 데이터프레임.head() : 데이터 미리보기 |
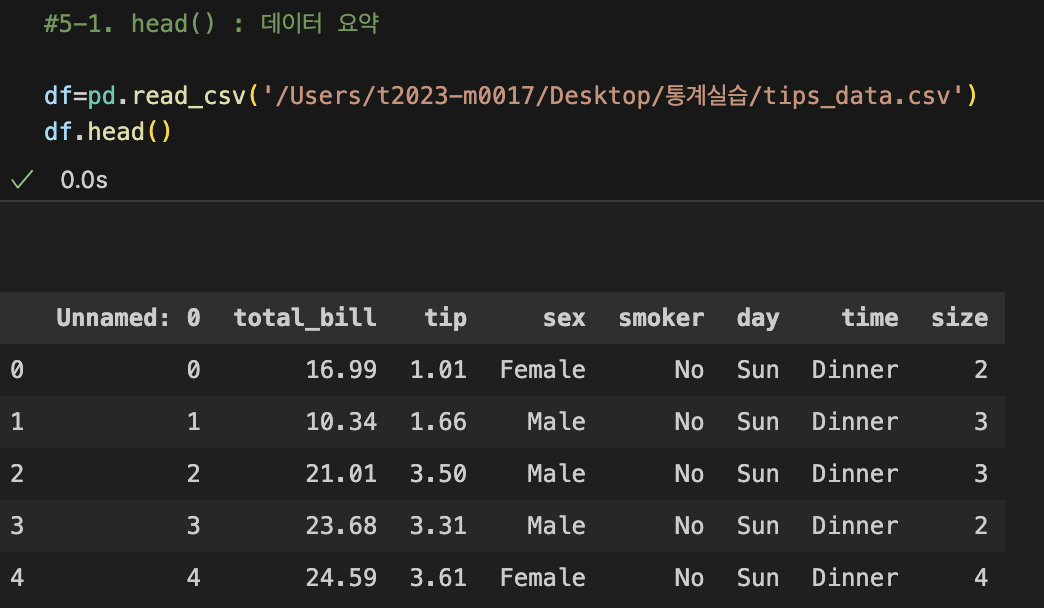 |
| 데이터프레임.info() : 데이터 정보(인덱스, 컬럼, null값 등) |
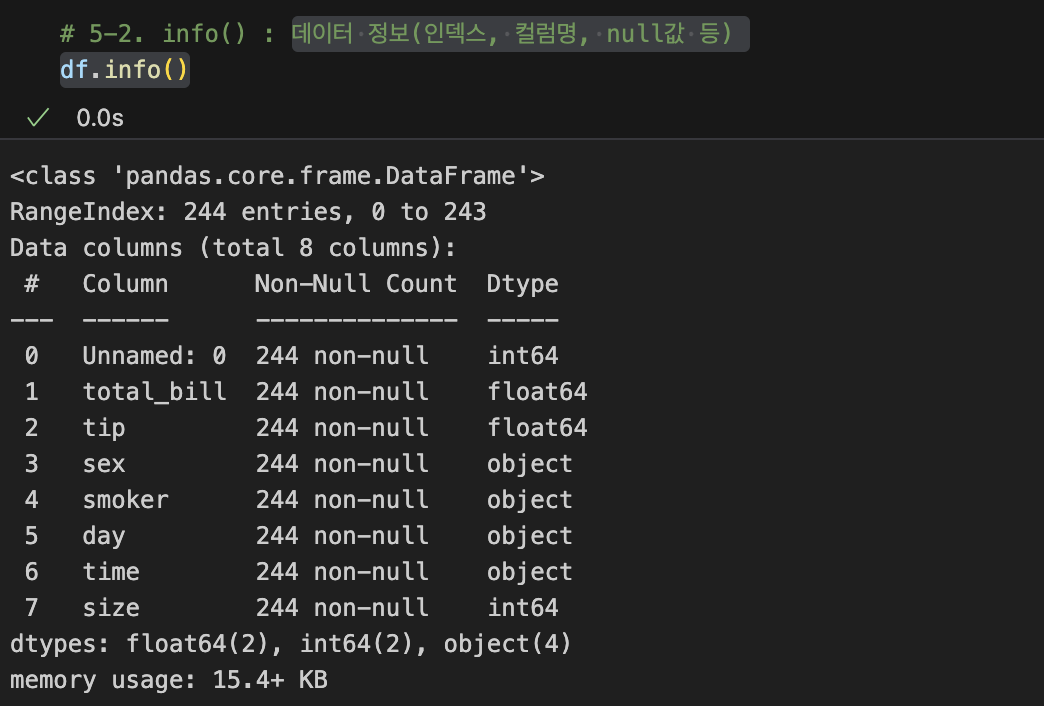 |
| 데이터프레임.describe(): 기초통계량( 평균, 중앙값, 수량 등) |
 |
4-2. 결측치 확인: .info(), isna()

| 데이터프레임.info() : null값 확인 1 B컬럼에는 null이 아닌 값이 3개 |
데이터프레임.isna() : null값 확인 2 -> null일 경우 True |
 |
 |
4-3. 데이터 타입 확인하기: .dtype
4-4. 데이터 타입 변경하기.astype()
| 컬럼에 대한 데이터 타입 확인 |  |
| 컬럼의 데이터 타입 바꾸기 float -> str |
to_datetime() |
 |
 |
5. 데이터선택: iloc, loc의 인덱스와 슬라이싱
5-1. iloc: 컬럼의 번호로
- 숫자로 익덱스를 인식
- 0번부터 시작하고, 마지막 인덱스는 출력X
| 데이터프레임 | df.iloc[0] #0번째 해당하는 인덱스의 값 |
 |
 |
| df.iloc[0:4:2] #0번째 인덱스부터 3까지(4는 포함 X), 2개씩 건너 뛰면서 #[시작:멈춤:보폭] #4컬럼에서 멈춤이니까 3컬럼까지 출력 |
df.iloc[0::2] #0부터 끝까지 2보폭으로 |
 |
 |
5-2. loc: 컬럼명으로
 |
df.loc['a':,'A'] #'a'인덱스부터 끝까지, A컬럼만 출력 |
df.loc['b':'d':2,'A':'C'] 'b'인덱스부터 'd'인덱스까지 2보폭으로, 컬럼A부터 C까지 |
 |
 |
|
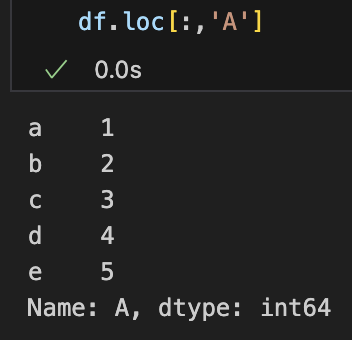
| df.loc[:, 'A'] #인덱스는 처음부터 끝까지, A컬럼만 |
df['A'] #인덱스는 처음부터 끝까지, A컬럼만 |
|
 |
 |
|
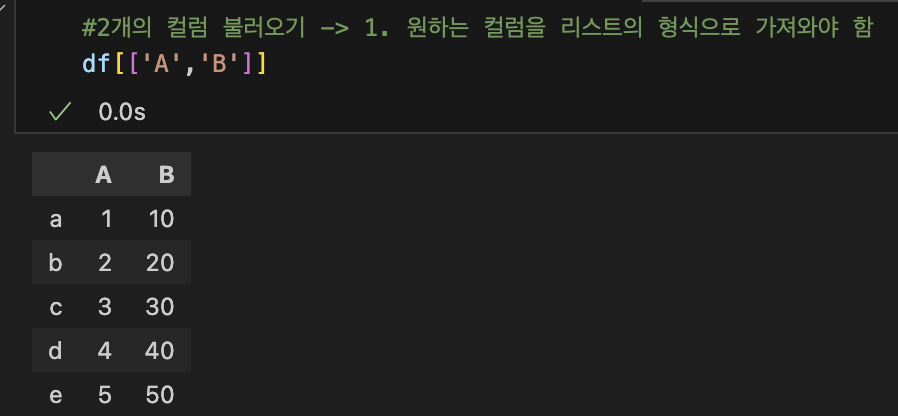
| #2개의 컬럼 불러오기-> 원하는 컬럼을 리스트로 불러옴 df[['A','B']] |
df[:,['A','B']] | |
 |
 |
5-3. 불리언 인덱싱: True/False
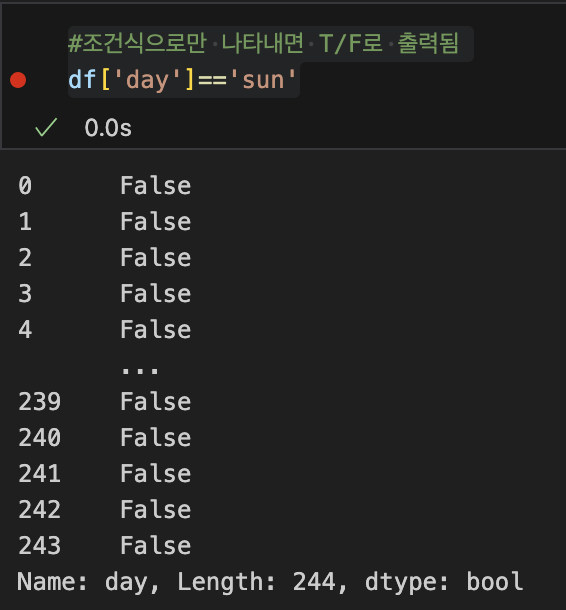
- 데이터 프레임에다 조건을 입력하면 참인 것만 불러옴
- 조건1이고 조건2 = 조건1 & 조건2
- 조건1 이거나 조건2 = 조건1 | 조건2
#성별이 남성 이고 흡염을 할 경우의데이터 and = &
df[(df['sex']=='Male') & (df['smoker']=='Yes')]
#size가 3이상인(조건) 'total_bill'부터'sex'까지의 컬럼 데이터(슬라이싱)
df.loc[df['size']>3, 'total_bill':'sex' ]
#size가 3이상인 'total_bill'와'sex'까지의 컬럼 데이터(원하는 컬럼을 리스트로)
df.loc[df['size']>3,['total_bill','sex' ]]
#사이즈가 1또는 2인 데이터
df[df['size'].isin([1,2])]
#일요일 목요일이 포함된 데이터
df[df['day'].isin(['Sun','Thur'])]
#condition이란 조건을 df에 반영하여 출력 -> tip이 2보다 작은 데이터만 출력
condition = df['tip']<2
df[condition]
# 조건이 여러개라면?
cond1 =df['size']>=3
cond2 = df['tip']<2
#['size']>=3이고 df['tip']<2인 데이터
df[cond1 & cond2]
# 2개의 조건을 하나의 변수에 저장할 때
cond=(df['sex']=='Male') \
& (df['tip']>3) \
&(df['smoker']=='Yes')
df[cond]
# 줄바꿈 기호 \
6. 데이터추가하기
1) 새로운 컬럼 추가
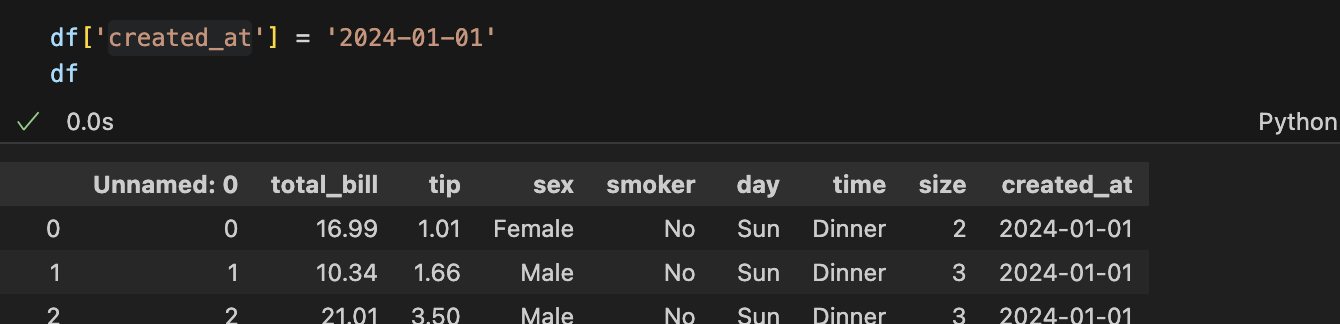
2) 연산을 통한 데이터 만들기
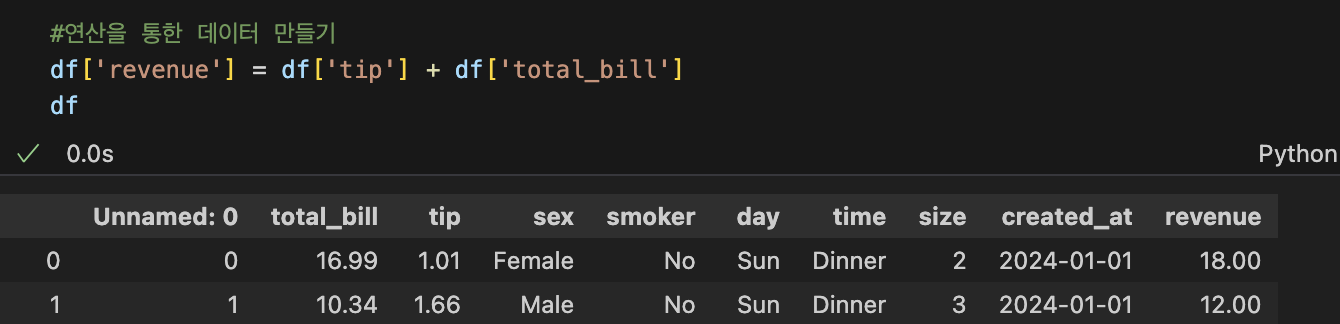
7. 데이터집계: groupby(), pivot_table()
7-1: groupby

- df.groupby('Category').mean() : Category별 평균 집계
- df.groupby('Category').sum() : Category별 합계 집계
- df.groupby('Category').count() : Category별 수량 집계
- df.groupby('Category').agg(list): Category별 데이터를 리스트 형태로 집계

|
#day의 데이터는 문자열로 계산할 수 없음
->에러 df.groupby('day').mean()
|
# day를 기준으로 'total_bill','tip','size'의 평균 df[['day','total_bill','tip','size']].groupby('day').mean() |
| TypeError: Could not convert MaleMaleFemaleFemaleF |  |
| #2개 이상의 컬럼을 그룹화지정 -> 리스트 #'day','sex'별 'total_bill','tip','size'의 평균 df[['day','sex','total_bill','tip','size']].groupby(['day','sex']).mean() |
#2개이상의 컬럼을 집계 ->agg #day','sex'별 total_bill'의 최대값, tip의 평균, size 수량 df[['day','sex','total_bill','tip','size']].groupby(['day','sex']).agg({'total_bill':'max','tip':'mean','size':'count'}) |
 |
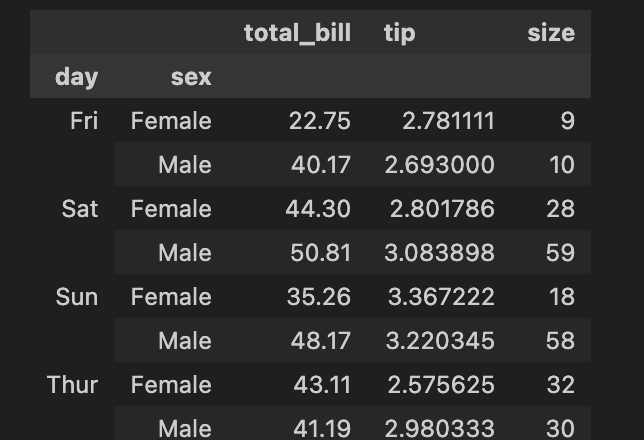 |
7-2: pivot_table
pt = pd.pivot_table(df,
index = 행 위치에 에 들어갈 컬럼
columns = 열 위치에 들어갈 컬럼
values = 데이터로 사용할 열
aggfunc = 데이터집계함수) |
|
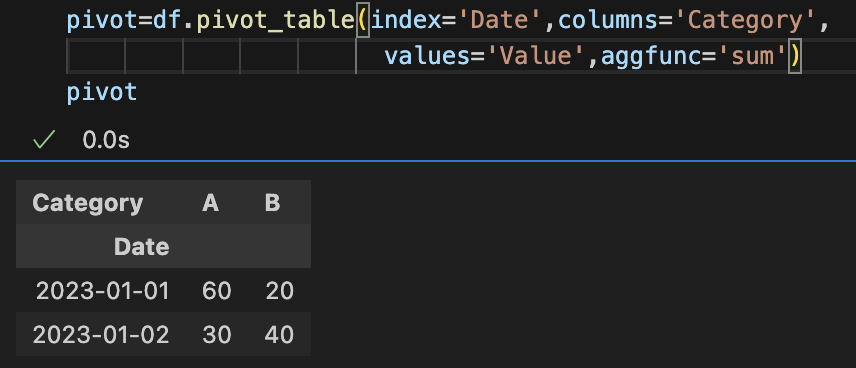 |
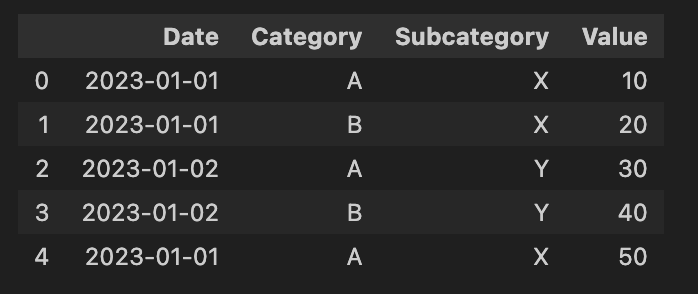 |
pivot = df.pivot_table(index='Date', columns=['Category','Subcategory'], values='Value',aggfunc='sum') |
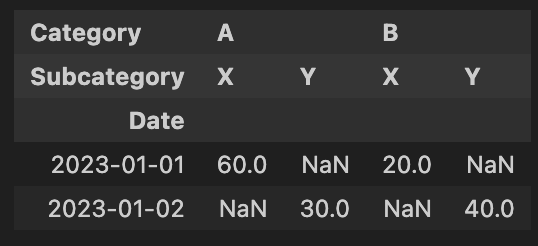 |
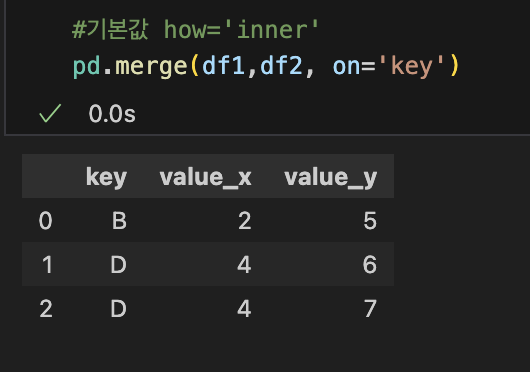
8. 데이터 병합: concat(), merge()
8-1. concat()
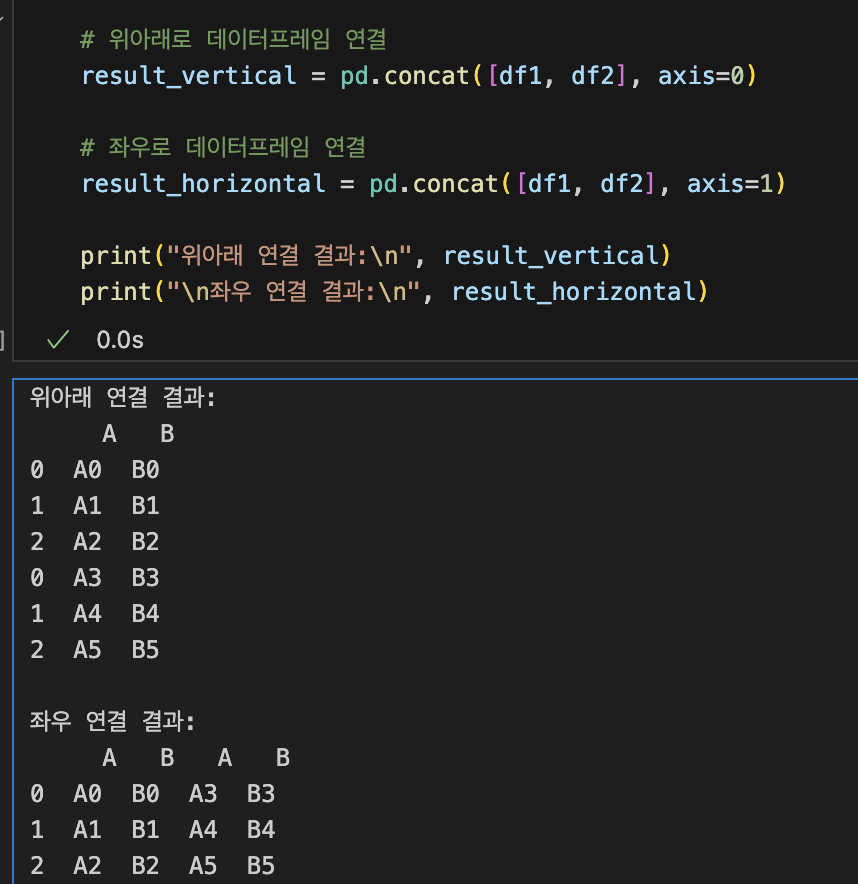
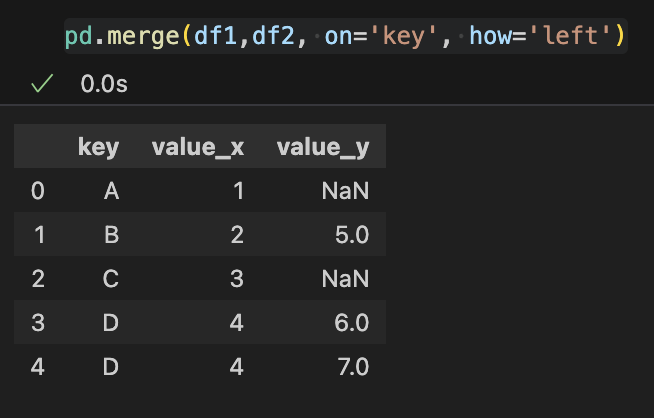
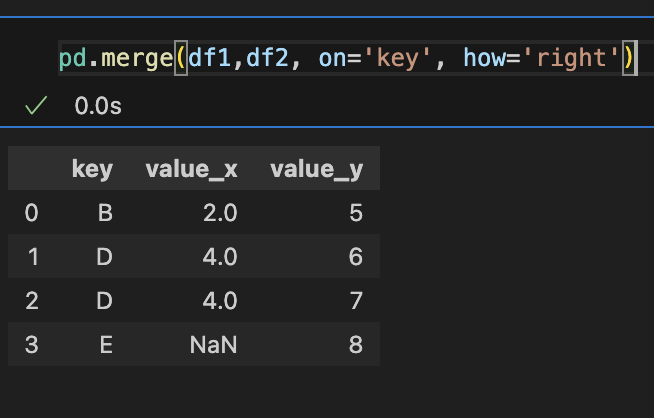
8-2. merge(): 특정값을 기준으로 병합
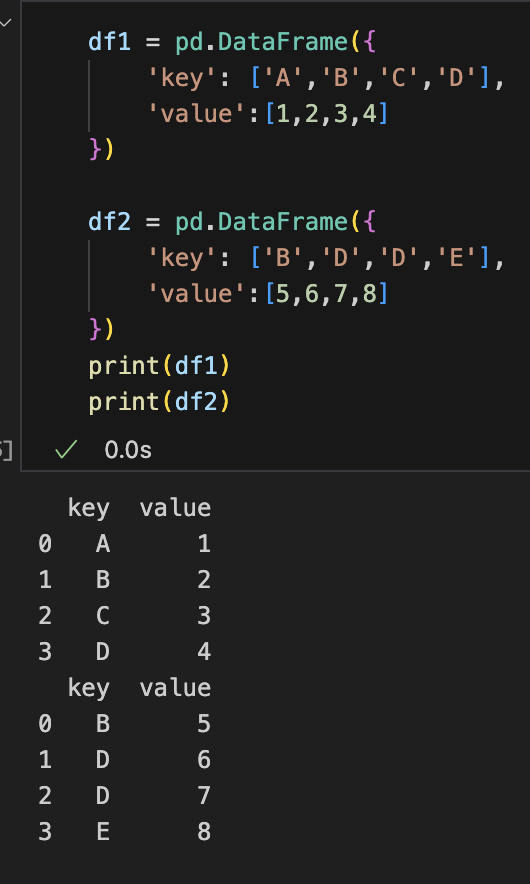 |
 |
 |
 |
 |
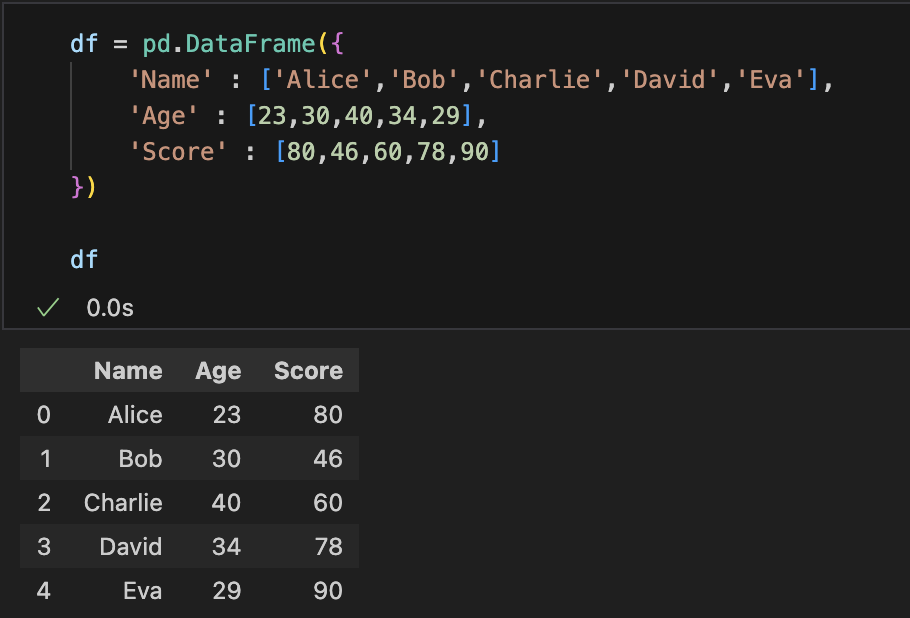
9. 데이터 정렬: sort()
 |
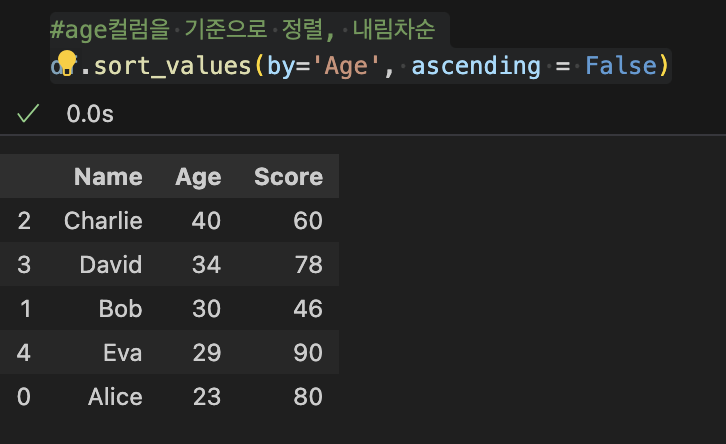 |
 |
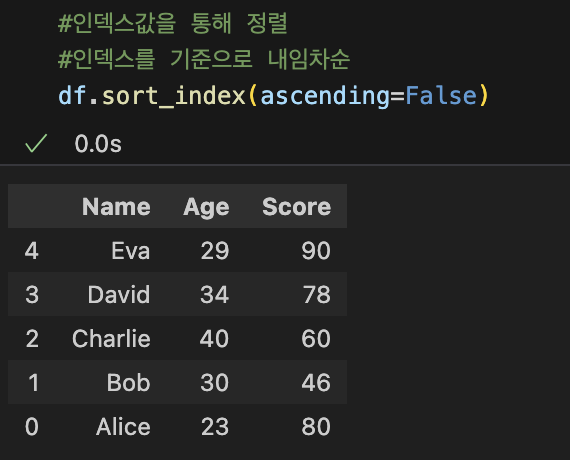 |
'학습노트 > Python' 카테고리의 다른 글
| [강의노트] Python - 머신러닝 - 선형회귀-실습(1) (2) | 2024.01.30 |
|---|---|
| [강의노트] Python - 머신러닝 - 선형회귀 (1) | 2024.01.30 |
| [강의노트] Python - 데이터전처리: pandas(1) (1) | 2024.01.23 |
| [강의노트] Python - Pandas, matplotlib 활용1 (1) | 2024.01.17 |
| [강의노트] Python 분석 - 상관계수 실습 (0) | 2024.01.16 |



