스파르타코딩클럽의 강의를 참고하여 정리하였습니다
데이터의 목적: 설득
데이터전처리
1. 데이터 분석 설계 : 무엇을 위해 어떤 형태의 데이터가 필요한가
- 목표설정하기: 무엇을 위해 데이터 전처리와 시각화가 필요한 것인가?
- 예상 산출물 정의하기: 데이터 처리 및 시각화해서 나타날 예상 결과물은 무엇인가?
- As-is(현재) VS To-be(이상) 생각하기: 현제 문제와 상황이 무엇인지 인지하고 어떤식으로 개선할 것인가 생각하며 분석 방향성 고려

2. 데이터 전처리
- 의미: 내가 원하는 데이터를 보기 위해 하는 모든 활동
- 목적: 데이터를 통해 얻고자(확인하고자) 하는것/의사결정을 위해 무엇이 필요한 것
3. Pandas: 데이터 전처리를 위한 도구
1) 판다스 및 데이터 불러오기
import pandas as pd
# pd.read_excel('파일경로/파일명.확장자')
# 엑셀 불러오기
pd.read_excel('./파일명.xlsx') # ./ ==> 현재 내가 있는 위치라는 의미
# csv 파일 불러오기
pd.read_csv('./파일명.xlsx')
💡pandas를 불러올 수 없는 경우: https://sixpeople.tistory.com/13
[Python] MAC Python Pip 맥에서 파이썬 pip설치하기 pip안될때
윈도우에서 아무생각없이 설치 했던 pip가 맥에서는 잘 깔리지 않는다. 내 맥에는 python버전이 2.7이 깔려 있었다. 아래와 같은 메세지가 뜬다. jed@MacBookAir ~ % pip zsh: command not found: pip 해결 방법 :해
sixpeople.tistory.com
2) 특징
- 대용량 데이터 처리가능
- 데이터조작 가능
- 데이터시각화 기능 제공: maplotlib, seaborn...
- 데이터를 구조화하여 분석가능(dataframe)
3) 구조

(1) dataframe: 표형태
- index: 각 아이템을 특정할 수 있는 고유의 값(엑셀의 열)
- columns: 하나의 속성을 가진 데이터 집합
(2) Series: dataframe에서 열이 1줄인 표
- 하나의 속성을 가진 데티어 집합
- index+value
(3) index: 데이터프레임 또는 시리즈의 각 행 또는 각 요소에 대한 식별자
- dataframe 자료구조에도 인덱스 설정 가능
- 0부터 시작하는 숫자 뿐아니라 임의로 문자로 적용가능
- 아예 처음부터 파일을 불러올 때, 인덱스 지정 가능
| 고유성 | 각 행은 유일한 인덱스 값을 가져야 함. 중복불가 |
| 불변성 | 불변성으로 한 번 생성된 인덱스는 변경불가(단, 새로운 값을 할당하여 기존대체는 가능) |
| 조작 및 탐색 | 인덱스를 사용하여 특정 행을 선책하거나 탐색 가능 |
| 정렬 | 인덱스를 사용하여 정렬가능 |
(3-1) 인덱스 설정하기
| 기본인덱스 |  |
||
| 사용자 지정 인덱스 |  |
||
| 인덱스 변경(대체) |  |
||
| 특정 인덱스의 행에 접근 | 인덱스를 기준으로 데이터프레임 정렬 | ||
 |
 |
||
(3-2) 인덱스 활용하기
- set_index(): 특정 컬럼에 들어있는 값을 인덱스로 활용
# df가 가지고 있는 특정 컬럼명을 기준으로 인덱스를 설정하기
data = df.set_index('컬럼명')
data.head()
# 불러올때 인덱스 지정하기
pd.read_csv('./data/file.csv' , index_col = '컬럼정보')
pd.read_csv('./data/file.csv' , index_col = 0) # 0부터 시작- 데이터프레임.index: 인덱스 확인 및 새로 입력
#인덱스 확인하기
data.index
#리스트 형태를 활용해서 인덱스를 새로 입력할 수 있습니다.
data.index = ['1번' , '2번' , '3번']
data- reset_index(): 현재 인덱스를 0부터 시작하는 정수로 변환
# reset_index() 의 기본 값은 drop = False 를 가지고 있습니다.
data.reset_index()
# 현재 인덱스를 컬럼으로 변경할 수 있습니다.
# reset_index(drop = True) 명령어를 활용하면,
# 현재 인덱스 값을 컬럼으로 변경하지 않고 인덱스를 초기화할 수 있습니다
data.reset_index(drop=True)
4) 컬럼
- 고유한 이름(라벨)을 가지고 있으며, 해당 컬럼의 데이터를 식별 하는데 사용
- 특정한 종유의 데이터를 담고 있으며 숫자, 문자열, 날짜 등 다양한 데이터 포함
- 시즈르 객체로 구성되어있으며, 시리즈는 동일한 데이터 유형을 가진 1차원 배열
- 데이터프레임의 일부로, 해당 열의 데이터를 조작하고 접근할 수 있는 인터페이스 제공
4-1) 컬럼 예시
import pandas as pd
# 데이터프레임 생성
data = {
'이름': ['Alice', 'Bob', 'Charlie'],
'나이': [25, 30, 35],
'성별': ['여', '남', '남']
}
df = pd.DataFrame(data)
| print(df['이름']) | print(df['나이']) | print(df['성별']) |
 |
 |
4-2) 컬럼 이름 변경하기
#1. name=[] 지정
pd.read_csv('./data/file.csv' , names = [’컬럼명1’, ‘컬럼명2’, … ,‘컬럼명 19’])
#2. 데이터프레임.column
df.column = ['name','age','sex']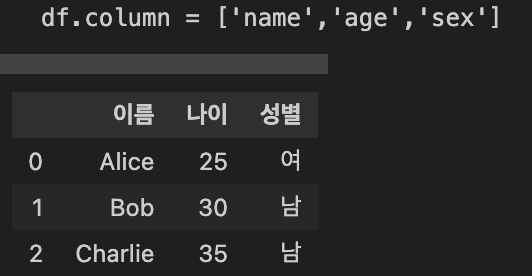
5) 데이터저장하기
df = 데이터프레임 # 저장하고 싶은 데이터
#pd.to_csv(’파일경로/파일명.확장자’ , index = False)
#pd.to_excel(’파일경로/파일명.확장자’ , index = False)
df.to_csv('./newfile.csv', index = False)
4. 데이터 확인
4-1) 데이터 확인방법: .head()/ .info() / .describe()
- 데이터의 결측치(null)가 있는지
- 데이터 타입에 알맞게 들어가 있는지 (날짜, 숫자 등)
- 데이터 통계도 목적에 따라 확인
| .head() : 데이터를n개 행까지 보여줌 |  |
data.head() # head()은 기본 5개 행에 대한 데이터를 보여줌 data.head(3) # ()안에 숫자만큼 데이터를 보여줌 |
| .info() : 데이터의정보(인덱스, 컬럼명, 개수, 타입) |  |
data.info() # null 값을 확인할때도 활용 |
| .describe() : 데이터의 기초 통계량(개수, 평균, 중앙값 등) |  |
data.describe() # 숫자값에 대해서만 기초통계량 확인이 가능합니다. |
4-2) 데이터 타입
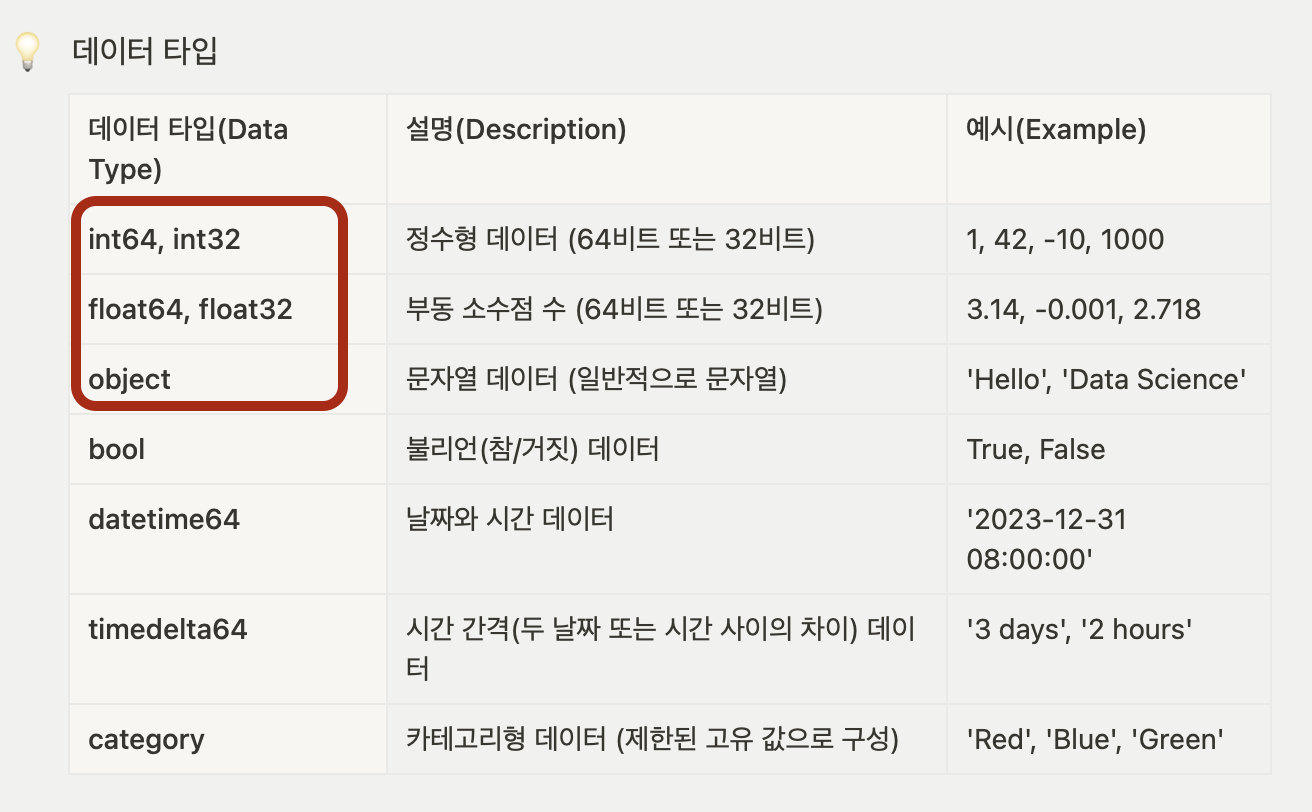
4-3) 데이터 타입 변경: astype()
astype() : 열의 데이터 타입을 원하는 형식으로 변환
DataFrame['column_name'] = DataFrame['column_name'].astype(new_dtype)
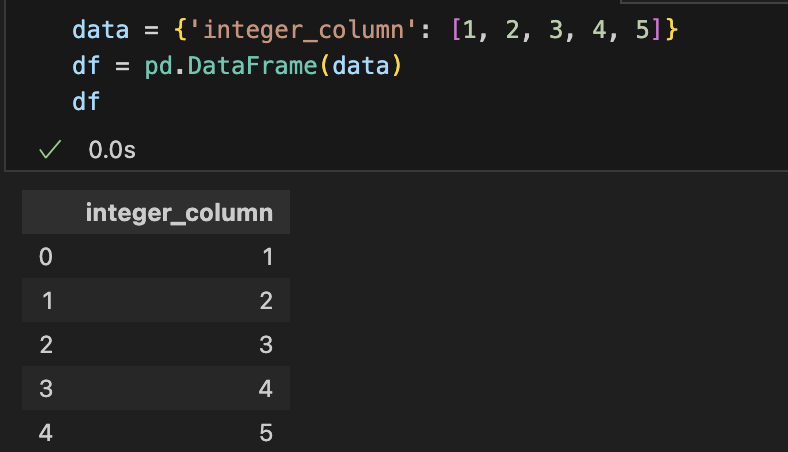
| int(정수) -> flaot(실수) | int(정수) -> str(문자) |
 |
 |
'학습노트 > Python' 카테고리의 다른 글
| [강의노트] Python - 머신러닝 - 선형회귀 (1) | 2024.01.30 |
|---|---|
| [강의노트] Python - 데이터전처리: Pandas(3) - 실습 (0) | 2024.01.25 |
| [강의노트] Python - Pandas, matplotlib 활용1 (1) | 2024.01.17 |
| [강의노트] Python 분석 - 상관계수 실습 (0) | 2024.01.16 |
| [강의노트] Python 분석- 상관계수(2), barplot (2) | 2024.01.14 |



