스파르타코딩클럽의 강의를 참고하여 정리하였습니다
사용데이터: seaborn시각화 라이브러리 기본 데이터 셋, tips
목표1. 주문의 전체 금액(total_bill)-> X 을 통해 받을 팁(tip)->y 예상하기
순서: 데이터획득 > 선형회귀 훈련하기 > 평가
방법: 단순선형회귀
💡순서
라이브러리 불러오기 > 데이터불러오기 > 선형회귀 훈련하기(산점도 그려보기, 가중치/편행 계산, 회귀식 계산, 예측값 계산, 회귀식/산점도 확인) > 평가하기(MES,z-score)
0. 라이브러리 불러오기
import sklearn
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
1. 데이터불러오기
tips_df = sns.load_dataset('tips')
tips_df.head(3)
# X: total_bill
# y: tip
2. 선형회귀 훈련하기
# 선형회귀 훈련(적합)
from sklearn.linear_model import LinearRegression
model_lr2 = LinearRegression()
X = tips_df[['total_bill']]
y = tips_df[['tip']]
model_lr2.fit(X,y)
- 산점도 그려보기 : 관계확인
sns.scatterplot(data = tips_df, x = 'total_bill', y= 'tip')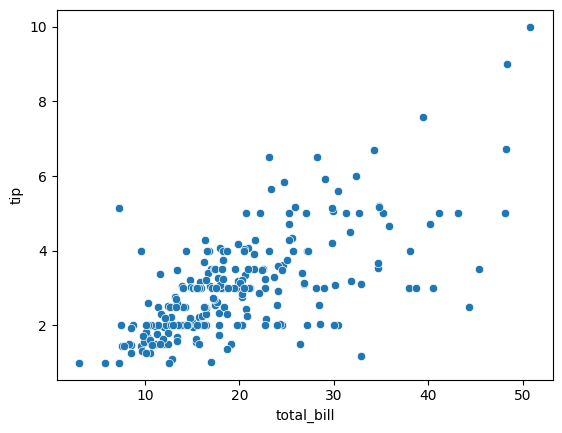
- 가중치, 편향 계산
# y(tip) = w1*x(total_bill) + w0
w1_tip = model_lr2.coef_[0][0]
w0_tip = model_lr2.intercept_[0]
print(w1_tip)
print(w0_tip)
# w1: 가중치
# w0: 편향>> w1: 0.10502451738435337
>> w0: 0.9202696135546731
-회귀식 계산
print('y = {}x + {}'.format(w1_tip.round(2), w0_tip.round(2)))
# y = 0.11x + 0.92
# 전체 결제금액이 1달러 오를때, 팁은 0.11달러 추가된다.
# 전체 결제금액이 100달러 오를때, 팁은 11달러 추가된다.
- 예측값 계산
# 예측값 생성 by .predict()
y_true_tip = tips_df['tip']
y_pred_tip = model_lr2.predict(tips_df[['total_bill']])
tips_df['pred'] = y_pred_tip
- 회귀식 및 산점도 확인
sns.scatterplot(data = tips_df, x = 'total_bill', y= 'tip')
sns.lineplot(data = tips_df, x = 'total_bill', y = 'pred', color = 'red')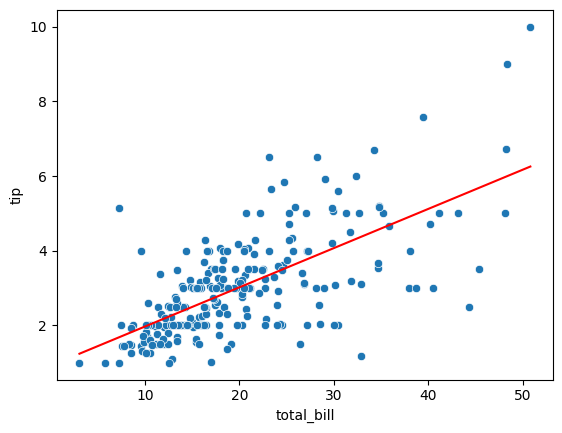
3. 평가하기
from sklearn.metrics import mean_squared_error, r2_score
- MES
mean_squared_error(y_true_tip, y_pred_tip)>> 1.036019442011377
- z-score
r2_score(y_true_tip, y_pred_tip)>> 0.45661658635167657
결과: 예측이 크게 맞지는 않은 것 같음(?) 더 효과적인 예측 방법은 없을 까?
목표2. 주문의 전체 금액(total_bill)-> x1 와 남여의 성별(sex) -> x2을 통해 받을 팁(tip)->y 예상하기
순서: 데이터획득>범주형 데이터 encoding > 선형회귀 훈련하기 > 평가
방법: 다중선형회귀
💡순서
라이브러리 불러오기 > 데이터불러오기 > 범주형 데이터 encoding> 선형회귀 훈련하기(산점도 그려보기, 가중치/편행 계산, 회귀식 계산, 예측값 계산, 회귀식/산점도 확인) > 평가하기(MES,z-score)
0. 라이브러리 불러오기
import sklearn
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
1. 데이터불러오기
tips_df = sns.load_dataset('tips')
tips_df.head(3)
# X: total_bill
# y: tip
2. 데이터 encoding하기 : 여자라면 0, 남자라면 1
# Female 0, Male 1
def get_sex(x):
if x == 'Female':
return 0
else:
return 1
#apply method는 매 행을 특정한 함수를 적용한다.
tips_df['sex_en'] = tips_df['sex'].apply(get_sex) #'sex'의 데이터에 get_sex함수를 적용하여 'sex_en'라는 새로운 컬럼을 만들어서 저장
tips_df.head(3)
3. 선형회귀 훈련하기
# 모델설계도 가져오기
# 학습
# 평가
model_lr3 = LinearRegression()
X = tips_df[['total_bill','sex_en']]
y = tips_df[['tip']]#학습
model_lr3.fit(X,y)#예측
y_pred_tip2 = model_lr3.predict(X)
y_pred_tip2[:5]
4. 평가하기
- MES
# 단순선형회귀 mse: X변수가 전체 금액
# 다중선형회귀 mse: X변수가 전체 금액, 성별
print('단순선형회귀', mean_squared_error(y_true_tip, y_pred_tip))
print('다중선형회귀', mean_squared_error(y_true_tip, y_pred_tip2))단순선형회귀 1.036019442011377
다중선형회귀 1.0358604137213614
- z-score
print('단순선형회귀', r2_score(y_true_tip, y_pred_tip))
print('다중선형회귀', r2_score(y_true_tip, y_pred_tip2))단순선형회귀 0.45661658635167657
다중선형회귀 0.45669999534149974
결론: 별 차이 없음...왜?
성별에 따라 팀의 차이가 별로 없기 때문,,
sns.barplot(data = tips_df, x = 'sex', y = 'tip')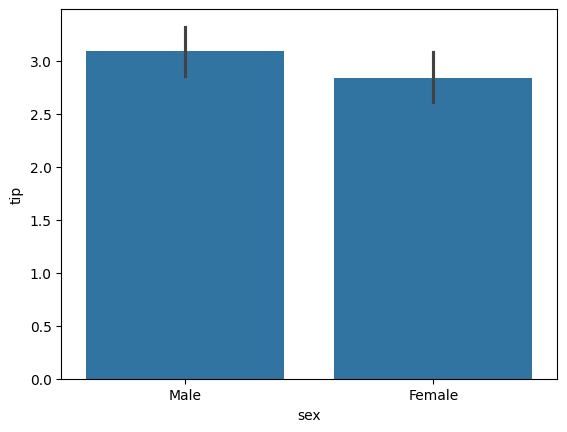
'학습노트 > Python' 카테고리의 다른 글
| [강의노트] Python - 머신러닝 - 로지스틱 회귀 (0) | 2024.01.31 |
|---|---|
| [강의노트] Python - 머신러닝 - 선형회귀-실습(2) (1) | 2024.01.30 |
| [강의노트] Python - 머신러닝 - 선형회귀 (1) | 2024.01.30 |
| [강의노트] Python - 데이터전처리: Pandas(3) - 실습 (0) | 2024.01.25 |
| [강의노트] Python - 데이터전처리: pandas(1) (1) | 2024.01.23 |



