스파르타코딩클럽에서 제공해주는 강의를 기반으로 요약하였습니다
변수선언
- 자료형: 프로그래밍을 할 때 쓰이는 숫자, 문자열 등 자료형태로 사용하는 모든 것
- 변수: 프로그래밍을 통해 문제를 해결하기 위해 처리할 자료나 결괏값을 보관하는 공간
- 대입연산자 = : =의 왼쪽의 변수에 저장하라
a = 10 # 10을 a에 넣는다
print(a) # a의 값을 조회한다
b = a # a에 들어있는 값인 10을 b에 넣는다
a = '가' # a에 새로운 값인 '가'를 넣는다
print(a,b) # 출력: 10 가 10
자료형-숫자형과 문자형
<기초연산>
a = 5
a = a + 3 # 5에 3을 더한 값을 다시 a에 저장
print(a) # 8
a += 3 # 줄여 쓸 수도 있다. 같은 의미!
a//b # 3 (몫)
a%b # 1 (나머지)
a**b # 49 (거듭제곱)
<심화>
숫자형 연산 문자열(문자들의모임) 연산 a = 7
b = 2- print('34'+'23')
print('34'+8)# 3423 연산자 +에 의해 서료 연결되어 출력
# 오류, 문자형+정수 불가!print(a+b)
print(a-b)
print(a*b)
print(a/b)# 9
# 5
# 14
# 3.5first_name = "kim"
last_name = "nana"
print(first_name + last_name)# Kimnana print(a+3*b) # 13 (여러 연산을 한 줄에 할 경우 사칙연산의 순서대로) print(len("abcde"))
print(len("Hello, Sparta!"))
print(len("안녕하세요."))# 5
# 14
# 6
len()함수는 문자열의 길이을 알 수 있다print((a+3)*b) # 20 (소괄호를 이용해서 연산 순위 지정) K = 'l like it'
print(K.upper())
print(K.lower())# L LIKE IT
# l like it
upper()/lower()은 대문자/소문자로 바꿀 수 있다
print(a//b)
print(a%b)
print(a**b)
a = a +3 과
a += 3 은 같은 의미# 3 (몫)
# 1 (나머지)
# 49 (거듭제곱)myemail = 'test@gmail.com'
result = myemail.split('@')
result[0]
result[1]
myemail.split('@')[1].split('.')[0]
*print 생략특정 문자열을 자르고 싶을 때
# ['test','gmail.com'] @을 기준으로 나눈다
# test @을 기준으로 0번째
# gmail.com @을 기준으로 1번째
'@'기준으로 1번째( gmail.com )->'.'을 기준으로 0번째(gmail)
<자료형 기타 함수 기능>
| 특정문자를 다른 문자로 바꾸기: test -> kim으로 변환 | N번째의 문자열 찾기(인덱싱과 슬라이싱) |
| myemail = 'test@gmail.com' print(myemail.replace('test','kim')) # kim@gmail.com |
f="abcdefghijklmnopqrstuvwxyz" print(f[1]) # b 파이썬은 숫자를 0부터 셉니다 print(f[1:3]) #bc 1부터 3자리 까지 print(f[:5]) #abcde 0자리부터 5자리까지 |
- 문자열을 나타낼 때는 따옴표("") 또는 작은 따옴표('') 사용 -> 따옴표를 사용하지 않을 경우 변수형으로 인식
- '2'의 경우 숫자가 아닌 문자열로 인식
- 참/거짓을 나타낼 때는 소문자가 아닌 대문자로 (true:변수명으로 인식하기 때문에 에러 -> True: 자료형으로 인식)
리스트
리스트: []대괄호 안에 저장된 순서가 있는 자료형들의 모임 (순서/인덱스는 0번쨰부터 시작)
- 리스트 지정: b = [3, "a", 6, 1]
- 리스트 저장: c = [] -> c.append[1,2,3] : 비어있는 c리스트에 1,2,3을 추가
- 리스트 추가: c.append["b"] -> c리스트에 (마지막 순서에)4 추가
인덱싱: 하나의 항목을 추출함 b[0] # 3
- 인덱싱을 통한 리스트 내용 수정 : b리스트 0번째 자리에 c로 수정 b[0] = c -> b[0] #c
- b리스트의 위치를 모를 경우 위치를 찾고 바꿔야 하나? replace처럼 바꿀 수 있는 건 없을까?
- 인덱싱을 통한 리스트 내용 추가 : b리스트 0번째 자리에 7을 추가 b.insert[0,7]
- 슬라이싱: 여러개의 항목을 추출하는 방법 b[0:1] #3.'a'
<리스트와 함수>
💡객체(변수).함수: 변수의(.) 함수 기능을 수행한다
| 리스트 (마지막순서에) 추가하기 변수.append(인덱스) |
리스트 (원하는 순서에) 추가하기 변수.insert(인덱스,항목) |
리스트 내림차순 절렬 변수.sort(reverse=True) |
리스트에서 인덱스 번호 찾기 변수.index(항목) |
| a = [1, 2, 3] a.append(5) # [1, 2, 3, 5] |
a = [1, 2, 3] a.insert(2,7) #[1,2,7,3] |
a = [2, 5, 3] a.sort(reverse=True) # [5, 3, 2] |
b.index(3) #1 0번째와 3번째 들어있는 1을 알고 싶은 경우? 인덱스 안 인덱스를 검색(2)할 경우 오류 [2,0]으로 검색 |
| 리스트의 길이 알기 len(변수) |
리스트 항목 삭제하기 변수.remove(항목) del[인덱스] 변수2=변수1.pop() *마지막 항목 삭제 |
리스트 안에 요소가 있는지 알고싶을 경우 print(요소 in 변수) |
|
| b = [1, 3, [2, 0], 1] print(len(b)) # 4 |
print(1 in b) # True |
딕셔너리
딕셔너리: {}중괄호 안에 저장되어 키(key)와 밸류(value)의 쌍으로 이루어진 자료 모임
- person = {"name":"Bob", "age": 21}
- 순서가 없기 때문에 인덱싱 사용 불가
- 키를 검색하면 밸류가 출력 print(person["name"]) #Bob
- 빈 딕셔너리 생성 (1) a={} (2) a=dict()
- 빈딕셔너리에 데이터 추가: (1) a["한글"] = "가나다" (2) a= {"한글":"가나다"}
- 딕셔너리 안에 키가 존재하는 지 알고 싶을 때: print("한글" in a)
<딕셔너리와 리스트>
💡 리스트 출력과 딕셔너리 출력
리스트 people = ["bob","carry"] 딕셔너리 people = {'name': 'bob', 'age': 20} bob를 출력하고 싶을 때
print(people[0])
-> 변수의 인덱스를 지정하여 출력bob를 출력하고 싶을 때
print(people["name"])
-> 변수의 key를 지정하여 value 출력
💡 딕셔너리는 리스트와 함께 쓰여 자료를 정리하는 데 쓰일 수 있다
people = [{'name': 'bob', 'age': 20}, {'name': 'carry', 'age': 38}]
# people[0]['name']의 값은? 'bob'
# people[1]['name']의 값은? 'carry'
person = {'name': 'john', 'age': 7}
people.append(person)
# people의 값은? [{'name':'bob','age':20}, {'name':'carry','age':38}, {'name':'john','age':7}]
# people[2]['name']의 값은? 'john'
❓carrydd의 math점수는?
people = [
{'name': 'bob', 'age': 20, 'score':{'math':90,'science':70}},
{'name': 'carry', 'age': 38, 'score':{'math':40,'science':72}},
{'name': 'smith', 'age': 28, 'score':{'math':80,'science':90}},
{'name': 'john', 'age': 34, 'score':{'math':75,'science':100}}
]
❗print(people[1]["score"]["math"]) #40
조건문
💡: -> 콜론은 아직 문장이 종료되지 않았다는 것을 의미, 코드블록이 이어서 등장한다
💡들여쓰기 -> 조건의 영향을 받는 문장
if문: 조건을 만족했을 때만 특정 코드가 실행하는 문법
score = 70
if score >= 60: #조건문 안끝났다
print("참 잘 했어요") #if 조건에 영향을 받음
print("you're good") #if 조건에 영향을 받음
elif score >= 40: #60미만이나 40이상의 경우
print("재도전하세요")
else: #40미만
print("공부가 필요합니다")
print("응시해 주셔서 감사합니다") #들여쓰기 x -> if 조건에 영향을 받지 않음 -> 그냥출력
반복문
- for 변수 in 리스트 : 리스트의 첫번째 항목부터 마지막 항목까지 차례로 변수에 대입하라
| <반복문> fruits = ['사과', '배', '감', '귤'] for fruit in fruits: # fuits리스트의 첫번때 항목부터 마지막 항목까지 차례로 변수 fruit에 대입하라 print(fruit) #반복문에 연결된 문장이기 때문에 들여쓰기 필수 |
<일반> fruits = ['사과', '배', '감', '귤'] print(fruits) |
| <출력> 리스트안에 있는 할목이 하나씩 모두 출력 사과 배 감 귤 |
<출력> 변수에 담긴 리스트 출력 ['사과', '배', '감', '귤'] |
❓리스트에서 나이가 20보다 큰 사람 출력하기
people = [
{'name': 'bob', 'age': 20},
{'name': 'carry', 'age': 38},
{'name': 'john', 'age': 7},
{'name': 'smith', 'age': 17},
{'name': 'ben', 'age': 27},
{'name': 'bobby', 'age': 57},
{'name': 'red', 'age': 32},
{'name': 'queen', 'age': 25}
]❗bobby. red. queen
for person in people: # people 리스트 안에 있는 딕셔너리를 하나씩 꺼내서 person의 변수에 입력
if person['age']>20: # (문장 이어짐)person딕셔너리의 age의 밸류가 20보다 크면
print(person['name']) # (문장 이어짐)person딕셔너리의 name의 밸류를 출력해줘
함수
- 함수: 반복적으로 사용하는 코드에 이름을 붙인 것(특정 기능을 구현하는 부분을 따로 떼어냄)
- def키워드를 통해 함수 정의 + 함수 이름 + ():
- 함수로 정의하면 언제든지 필요할 때 함수를 불러서 문제처리가 가능
- 매개변수=파라미터 라고도 함
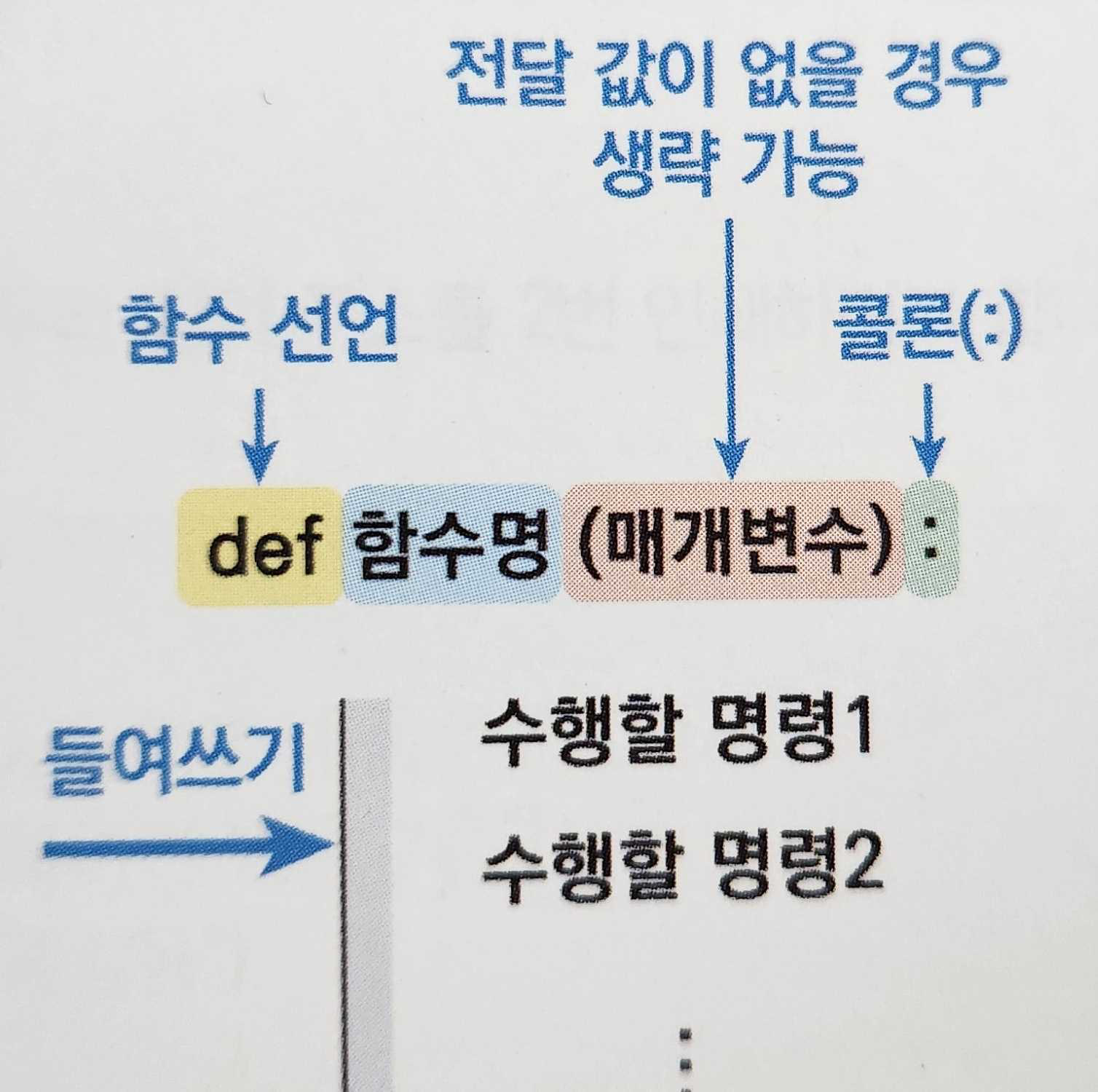
def hello(): #hello 함수 정의
print("안녕!") #수행할 명령1
print("또 만나요!") #수행할 명령2
hello()
| 동일한 코드 |
결과 | ||
| def hello(): print("안녕!") print("또 만나요!") hello() hello() |
print("안녕!") print("또 만나요!") print("안녕!") print("또 만나요!") |
for i in range(2): print("안녕!") print("또 만나요!") |
안녕! 또 만나요! 안녕! 또 만나요! |
💡응용1. 조건문에 넣을 값을 바꿔가면서 결과를 확인 할 때
- def bus_rate(age): 함수이름(bus_rate)이름 뒤의 소괄호 중간에 변수 age가 있습니다. 이 변수 age에 함수로 저장된 값(35)이 저장됩니다.
- bus_rate(35): 메인 프로그램에서 bus_rate( )를 호출할 때 35라는 숫자를 변수 age에 전달하고 있습니다.
def bus_rate(age): #age라는 매개변수와 관련된 함수를 bus_rate에 저장
if age > 65:
print("무료로 이용하세요.")
elif age > 20:
print("성인입니다. 1450원")
else:
print("청소년 입니다. 1000원")
bus_rate(35) #35라는 인수를 지정하여 매개변수에 전달
💡응용2. 단순 출력 뿐 아니라 결과 값을 돌려주도록 할 때
def bus_free(age): #age변수와 관련된 함수를 bus_free에 저장
if age > 65: #age가 65를 넘으면
return 0 #0을 저장!
elif age > 20:
return 1200 #1200으로 값을 저장
else:
return 0 #0으로 값을 저장 #print의 경우 보여주기만 하고 저장하지 않음
money = bus_free(21) #return에 저장된 값을 money에 저장
print(money)
💡Print() 와 return의 차이
| print() | return |
| def bus_free(age): if age > 65: print(0) elif age > 20: print(1200) else: print(0) money = bus_free(21) print(money) |
def bus_free(age): if age > 65: return 0 elif age > 20: return 1200 else: return 0 money = bus_free(21) print(money) |
| 출력 : None print()의 경우 단순 출력만 하기 때문에 변수에 담을 수 없다 즉, 변수money에는 담긴게 없기 때문에 아무것도 없다는 none 표시 |
출력: 1200 bus_free(21)의 값이 저장되어 변수 money에 담겼기 때문 |
궁금한점
함수(예:len())와 메소드(예: append)의 차이
'학습노트 > Python' 카테고리의 다른 글
| [강의노트] Python - Pandas, matplotlib 활용1 (1) | 2024.01.17 |
|---|---|
| [강의노트] Python 분석 - 상관계수 실습 (0) | 2024.01.16 |
| [강의노트] Python 분석- 상관계수(2), barplot (2) | 2024.01.14 |
| [강의노트] Python 분석 - 상관계수(1) (1) | 2024.01.14 |
| [강의노트] Python - 기초문법(1) - 실습 (0) | 2024.01.06 |



