2.1 임의표본추출과 표본편향
표본 sample: 더 큰 데이터 집합으로부터 얻은 부분집합
모집단 population :어떤 데이터 집합을 구성하는 전체 혹은 전체 집합
n :모집단의 크기
임의표본추출(임의표본, 랜덤표본추출) ramdom sampling:무작위로 표본을 추출하는 것
층화표본추출(층화표집) stratified sampling :모집단을 층으로 나눈 뒤, 각 층에서 무작위로 표본을 추출하는 것
계층: 공통된 특징을 가진 모집단의 동종 하위 그룹
단순임의표본 : 모집단 층화 없이 임의표본추출로 얻은 표본
편향 bias : 계통상의 오류
표본편향 sample bias : 모집단을 잘못 대표하는 표본
-> 첫번째 표본과 동일한 방식으로 추출된 다른 샘플에서도 모집단과 표본사이의 차이가 계속 유의미하게 큰 것
복원추출 with replacement : 추출 후 다음번에도 중복 추출이 다능하도록 해당 샘플을 다시 모집단에 포함
비복원추출 without replacement : 한번 추출된 원소는 추후 추첨에 사용하지 않는 것
1) 편향
통계적 편향 : 측정과정 혹은 표본추출과정에서 발생하는 계통적인(systematic) 오차
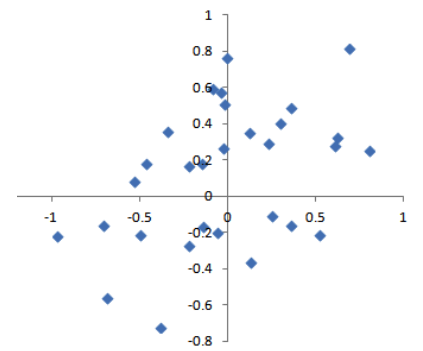 |
 |
| 정확하지는 않지만 어느한쪽에 치우치지 않음 | X,Y방향에서 랜덤한 오차가 있지만 1사분면에 쏠리는 편향 |
표본오차와 비표본오차
1) 표본오차 : 모집단과 표본의 자연발생적 변동, 모집단의 모수와 표본의 통계량간의 차이로 인해 통계치가 모수치의 주위에 분산되어 있는 정도
표본오차의 원인: 우연, 표본수의 부족
2) 비표본오차 : 자연발생적인 표본오차를 제외한 변동, 편향으로 부터 발생한 오차
비표본오차의 원인 : 조사원의 미숙, 잘못된 해석, 편향(표본추출편향, 가구편향, 무응답편향, 응답편향, 브래들리 효과)
3) 인지적 편향 : 분석가의 성향이나 상황에 따라 비논리적으로 추론을 내리는 패턴
사례: 확증편향, 기준점 편향, 선택지원편향, 분모편향, 생존자 편향
https://velog.io/@chlwlsgh93/%EB%AA%A8%EC%A7%91%EB%8B%A8%EA%B3%BC-%ED%91%9C%EB%B3%B8%EC%B6%94%EC%B6%9C
*데이터사이언스 편향분석 사례
https://dbr.donga.com/article/view/1206/article_no/10401/ac/magazine https://velog.io/@chlwlsgh93/%EB%AA%A8%EC%A7%91%EB%8B%A8%EA%B3%BC-%ED%91%9C%EB%B3%B8%EC%B6%94%EC%B6%9C
모집단과 표본추출
2.1 모집단과 표본, 전수조사와 표본조사 > 모집단(population) : 분석 대상 전체 집합 표본(sample) : 모집단의 일부 > 전수조사 : 모집단 자료 전체 조사 및 분석하여 정보 추출(선거 투표) 표본조사 :
velog.io
2) 모집단과 표본편차
표본은 관찰을 통해 얻어지고 , 모집단에 대한 정보는 작은 표본들로부터 추론하기 때문에 두 가지를 구분

2.2 선택편향
선택편향 : 관측데이터를 선택하는 방식 때문에 생기는 편향
데이터 스누핑 : 원가 흥미로운 것을 찾아 광범위하게 데이터를 살피는 것
방대한 검색 효과 : 중복 데이터 모델링이 너무 많이 예측변수를 고려하는 모델링에서 비롯되는 편향
-> 방지 : 홀드아웃, 목푯값섞기(순열검정)
1) 평균으로의 회귀(돌아간다 <> 선형회귀 : 예측변수와 결과변수 사의의 선형적 관계를 추정하는 방법)
주어진 어떤 변수를 연속적으로 측정했을 때 나타나는 현상(예외적인 경우가 관찰되면 그 다음에는 중간정도의 경우가 관찰되는 경향)
🎈주요개념
가설을 구체적으로 명시하고 임의표본추출원칙에 따라 데이터를 수집하면 편향을 피할 수 있다
모든 형태의 데이터 분석은 데이터 수집/분석 프로세스에서 생기는 편향의 위험성을 늘 갖고 있다
2.3 통계학에서의 표본분포
표본통계량 : 더 큰 모집단에서 추출된 표본 데이터들로부터 얻은 측정 지표
데이터분포 : 어떤 데이터 집합에서의 각 개별 값의 도수분포
표본분포 : 여러 표본들 혹은 재표본들로부터 얻은 표본통계량의 도수분표
중심극한정리 : 표본크기가 커질수록 표본평균의 분포가 정규분표를 따르는 경향
표준오차 : 통계에 대한 표본분포의 변동성을 표현하는 단일 측정 지표), 표본평균의 표준편차
-> 계산 : 표준편차(관측값과 표본 평균의 차이)를 표본크기의 제곱근으로 나눈 값, 표본 통계량의 표분편차

-> 의미 : 표본의 평균이 얼마나 모평균에 가까운지 나타내는 지표
*변량 : 연구나 관찰 대상에서 관심을 가지는 속성 또는 특성(예: 나이, 키, 성적 등)
표본평균 : 모집단에서 n개 추출한 표본의 평균
평균과 같은 표본통계량의 분포는 데이터 자체의 분포보다 규칙적이고 종 모양일 가능성이 높다
-> 중심극한정리: 표본의 크기가 충분히 크면 표본평균의 분포가 정규분포에 가까워짐
-> 표본평균의 분포가 모평균을 중심으로 대칭적이고 종 모양의 분포를 가지게 되는 것
표본이 클수록 표본통계량의 분포가 좁아진다
-> 표본의 크기가 증가할수록 표본평균이 모평균을 더 잘 추정하기 때문에 표본평균의 표준편차가 감소하여 분포가 좁아짐
-> 즉, 표준오차의 감소: 표준오차는 표본의 크기에 반비례하여 감소
-> N제곱근 법칙 : 표준오차를 2배 줄이려면 표본크기를 4배 증가시켜야 함
모집단: 대출신청자
랜덤 5명의 평균보다 20명의 평균이 모평균과 더 유사하여 표본들의 표준편차가 감소함 -> 더 뾰족
| (데이터 분포) 1000명의 소득 히스토그램 |
(표번분포) 5명을 추출하여 평균(표본평균)값 1000개 |
(표번분포) 20명을 추출하여 평균(표본평균)값 1000개 |
 |
 |
 |
1) 중심극한정리
모집단이 정규분포가 아니더라도 표본의 크기가 충분히 크고 데이터가 정규성을 크게 이탈하지 않을경우,
여러 표본에서 추출한 평균은 정규곡선을 이룬다
-> 표본의 크기가 충분히 크면 표본평균의 분포가 정규분포에 가까워 지는 것
-> 활용:신뢰구간, 가설점정계산 등
🎈 주요개념
표본통계량의 도수분포는 그 해당 지표가 표본마다 다르게 나타낼 수 있름
부스트랩 방식, 중심극한정리에 의존하는 공식을 통해 표본분포를 추정 가능
표준오차는 표본 통계량의 변동성을 요약하는 것
-> 실질적으로 표준오차를 추정하기 위해 새 샘플을 수집하는 것은 불가능 -> 대안 : 부트스트랩
2.4 부스트랩
모수의 표본분포를 추정하는 효과적인 방법으로 표본을 복원추출하여 통계량과 모델을 다시 계산하는 것
-> 데이터나 표본통계량이 정규분포를 따를필요 없음
-> 복원추출 장점: 원소가 폽힐 확율을 그대로 유지하면서 큰 모집단 형성 가능
부트스트랩 표본: 관측데이터 집합으로부터 얻은 복원추출
재표본추출(재표집, 리샘플링) : 관측데이터로부터 반복해서 표본을 추출하는 과정(여러표본이 결합되어 비복원추출을 수행할 수 있는 순열과정을 포함)
*부트스트랩은 항상 관측된 데이터로부터 복원추출
🎈 주요개념
부트스트랩은 표본통계량의 변동성을 평가하는 강력한 도구
부트스트랩은 수학적 근사가 어려운 통계량에서도 샘플링 분포 추청이 가능
예측 모델시 여러 부트스트랩 표본들로부터 얻은 예측값을 모아서 결론을 만드는 것(배깅)이 단일 모델보다 좋다
면접질문
Q. 샘플링은 무엇인가요?
표본추출을 의미하여, 모집단 전체에 대한 조사는 불가능하기 때문에 모집단에 대한 정보를 얻기위해 일부를 선택해서 고르는 일 (미지의 모집단에서 알 수 있는 표본데이터를 가져오는 것)
-> 데이터 편향을 최소화 하는 것이 중요
Q. 샘플링 하는 방법은 무엇인가요?
단순확률추출, 계통추출, 층화추출, 군집/집락추출
Q. 중심극한정리란 무엇인가요?
표본의 크기가 충분히 크면 표본평균의 분포가 정규분포에 가까워 지는 것
Q. 중심극한정리는 왜 유용한가요?
통계적으로 표본 평균의 분포를 정규분포로 가정하고 통계적 추론이 가능 +a...