Prophet
공식문서 : https://facebook.github.io/prophet/
Prophet
Prophet is a forecasting procedure implemented in R and Python. It is fast and provides completely automated forecasts that can be tuned by hand by data scientists and analysts.
facebook.github.io
메타에서 공개한 시계열 예측 라이브러리
시간에 따른 트렌드, 계절성, 휴일효과등을 반영하여 미래의 값을 예측할 수 있음
y(t) = g(t) + s(t) + h(t)
- g(t): 트렌드 모델, 주기성을 포함한 시간에 따른 변동
- s(t): 계절성 구성요소 모델, 주기성
- h(t): 휴일 효과 모델, 휴일에 따른 추가적인 변동
- ε(t): 오차항, 모델에서 설명하지 못하는 잔차
💡 Prophet 매개변수의 기본값
- changepoints: None
- n_changepoints: 25 ,구조 변화를 설정할 때 사용할 차례 수
- changepoint_range: 0.8,구조 변화가 발생할 수 있는 기간의 비율
- yearly_seasonality: 'auto' ,연간 계절성을 자동으로 감지
- weekly_seasonality: 'auto',주간 계절성을 자동으로 감지
- daily_seasonality: 'auto',일일 계절성을 자동으로 감지
- seasonality_mode: 'additive'-데이터의 잔폭이 일정/반대 - multivate-데이터의 잔폭이 점점 증가
- seasonality_prior_scale: 10.0, 계절성 모델의 유연성을 제어하는 매개변수
- holidays: None-휴일 이벤트를 고려X
prophet 모델 성능평가
MSE(Mean Squared Error)
회귀 모델의 성능을 평가하는 지표로,
예측값과 실제값의 차이를 제곱하여 평균화한 값
APPLE 모델링하기
1차 시도
학습데이터 start = 2021-01-01 end = 2023-06-30(상승추세)
테스트데이터 start=2021-01-01 end=2024-03-04

1차 모델링
# 파라미터 조정 없는 학습 future_apple, forecast_apple
model_apple = Prophet()
model_apple.fit(df_apple)
fcast_time = 365 #365 일예측
future_apple = model_apple.make_future_dataframe(periods = fcast_time, freq = 'D')
forecast_apple = model_apple.predict(future_apple)
# 시각화 : 파라미터 조정 없는 학습 future_apple, forecast_apple
# 파란선이 예측한 값, 검정색이 실제 데이터
fig1 = model_apple.plot(forecast_apple)# 요소
plt.figure(figsize=(10, 5))
plt.fill_between(x=test_set['Date'], y1=test_set['yhat_lower'], y2=test_set['yhat_upper'], color='lightblue')
sns.lineplot(data=test_set, x='Date', y='Close', color='black')
sns.lineplot(data=test_set, x='Date', y='yhat', color='blue')
plt.title('APPLE')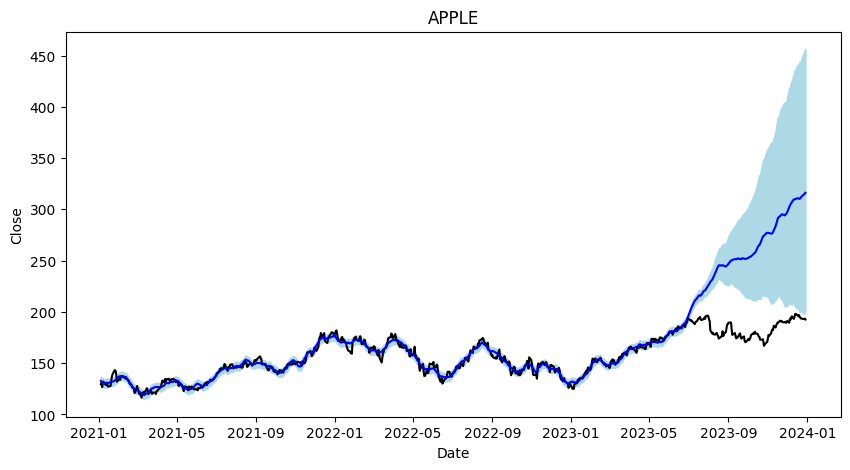
23년 1월부터 크게 상승후 9월부터 정체된 실제 주가와 달리 예측주식은 계속 상슬할 것으로 판단
-> 학습기간의 마지막 추세를 많이 반영한것 같다
1차 모델 성능 검사
#테스트 데이터셋 검증
# MSE가 0이라면 예측 모델은 완벽하게 실제값을 예측하는 것이며, MSE가 크다면 예측 오차가 크다는 것을 의미
from sklearn.metrics import mean_squared_error
mse_test = mean_squared_error(test_set['Close'], test_set['yhat'])
mse_test>>> 1145.4836000407536
2차 시도
학습데이터 start = 2021-01-01 end = 2023-09-30(하락추세)
테스트데이터 start=2021-01-01 end=2024-03-04
2차 모델링
model_apple= Prophet(
# trend -> 높을수록 디테일하게 확인, 0.5보다 커지면 오차가 커짐
changepoint_prior_scale= 0.5,
# seasonality
yearly_seasonality = 20,
# weekly는 10이상 일 경우 오차가 커짐
weekly_seasonality = 10,
# 토,일에 거래가 없는 요일 반영
daily_seasonality = True,
seasonality_prior_scale=10, #10이상일경우 오차가 커짐
seasonality_mode='additive')
# 주가는 연도별로 증가하는 경향이 크기 때문 -> 그러나 23년 전까지 크게 변화가 애플에게는 multiplicative는 안맞을듯)
# 미국의 휴일 설정
model_apple.add_country_holidays(country_name='US')
# 학습
model_apple.fit(df_apple)
future_apple = model_apple.make_future_dataframe(periods = fcast_time, freq = 'D')
forecast_apple= model_apple.predict(future_apple)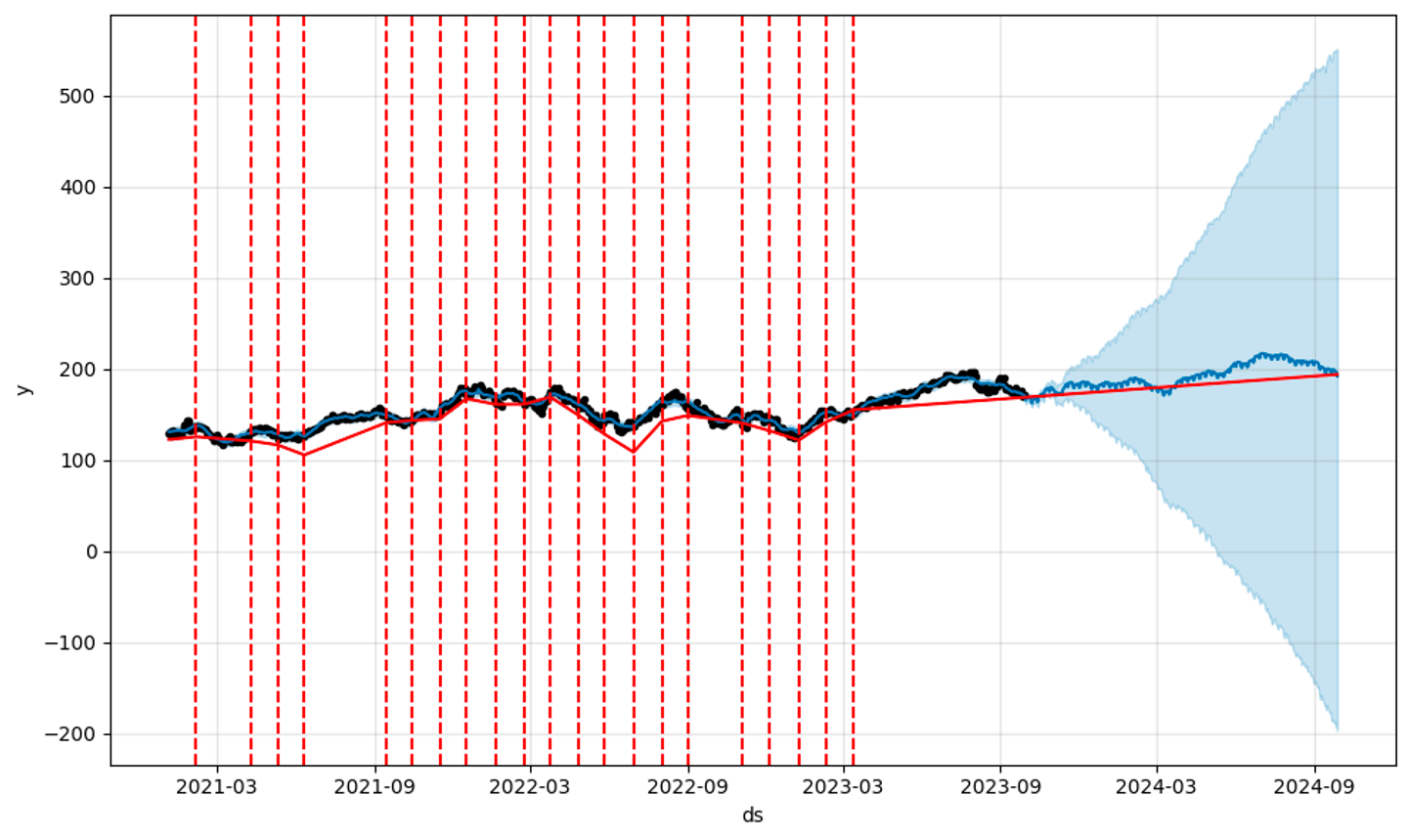
2차 모델 성능 검사
# 테스트를 위한 start='2021-01-01', end='2024-03-04'의 데이터
apple = yf.download('AAPL', start='2021-01-01', end='2024-03-04')
test_set = pd.merge(apple, forecast_apple, how='inner', on='Date')
#테스트 데이터셋 검증
# MSE가 0이라면 예측 모델은 완벽하게 실제값을 예측하는 것이며, MSE가 크다면 예측 오차가 크다는 것을 의미
from sklearn.metrics import mean_squared_error
mse_test = mean_squared_error(test_set['Close'], test_set['yhat'])
mse_test
>>> 18.312049744884167
-> 많이 낮아졌다
-> 마지막 학습 기간에 따라 영향을 많이 받는다
AMAZON 모델링하기
학습데이터 start = 2021-01-01 end = 2023-09-30(하락추세)
테스트데이터 start=2021-01-01 end=2024-03-04
1차 기본값으로 모델링
# 파라미터 조정 없는 학습 future_apple, forecast_apple
model_amazon = Prophet()
model_amazon.fit(df_amazon)
fcast_time = 365 #365 일예측
future_amazon = model_amazon.make_future_dataframe(periods = fcast_time, freq = 'D')
forecast_amazon = model_amazon.predict(future_amazon)
# 시각화 : 파라미터 조정 없는 학습 future_apple, forecast_apple
# 파란선이 예측한 값, 검정색이 실제 데이터
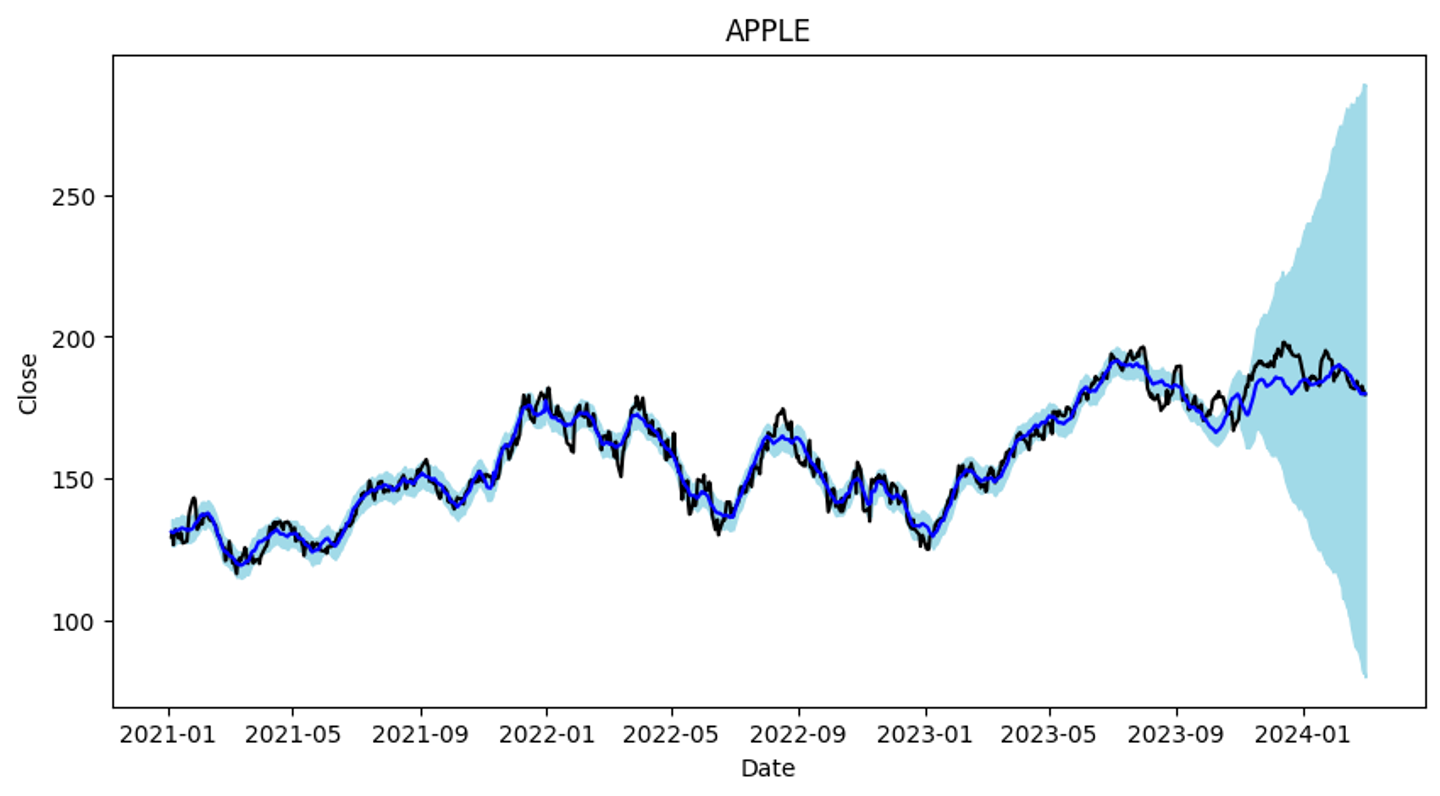
fig_am = model_amazon.plot(forecast_amazon)# 요소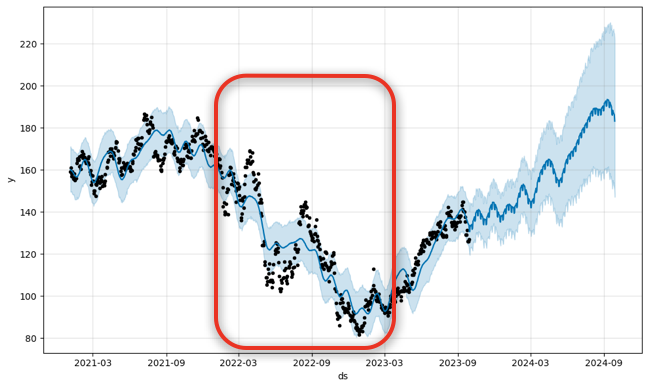
각 데이터의 진폭이 21년도보다 22년도에 훨씬 커짐
-> 주가가 21년도 보다 22년도에 큰 범위에서 변동
1차 기본값 성능평가
-> 학습시간이후(9월) 상승추세를 잘 반영하지 못함
# 성능평가를 위한 전처리
forecast_amazon['Date'] = forecast_amazon['ds']
# 테스트를 위한 start='2021-01-01', end='2024-03-04'의 데이터
amazon = yf.download('AMZN', start='2021-01-01', end='2024-03-04').reset_index()
test_set_amazon = pd.merge(amazon, forecast_amazon, how='inner', on='Date')
#테스트 데이터셋 검증
# MSE가 0이라면 예측 모델은 완벽하게 실제값을 예측하는 것이며, MSE가 크다면 예측 오차가 크다는 것을 의미
from sklearn.metrics import mean_squared_error
mse_test_amazon = mean_squared_error(test_set_amazon['Close'], test_set_amazon['yhat'])
mse_test_amazon
>>> 80.57088943742133
2차 모델링
prophet 매개변수중 seasonality_mode반영
model_amazon2= Prophet(
# trend -> 높을수록 디테일하게 확인, 0.5보다 커지면 오차가 커짐
changepoint_prior_scale=0.05,
# seasonality
yearly_seasonality = 15,
# weekly는 10이상 일 경우 오차가 커짐
weekly_seasonality = 15,
# 토,일에 거래가 없는 요일 반영
daily_seasonality = True,
seasonality_prior_scale = 20, #20 이하일경우 오차가 커짐
seasonality_mode = 'multiplicative')
# 아마존는 연도별로 증가하는 경향이 큼(데이터의 진폭커짐)-> multiplicative 더 최적
# 미국의 휴일 설정
model_amazon2.add_country_holidays(country_name='US')
# 학습
model_amazon2.fit(df_amazon)
future_amazon2 = model_amazon2.make_future_dataframe(periods = fcast_time, freq = 'D')
forecast_amazon2= model_amazon2.predict(future_apple)2차 성능평가
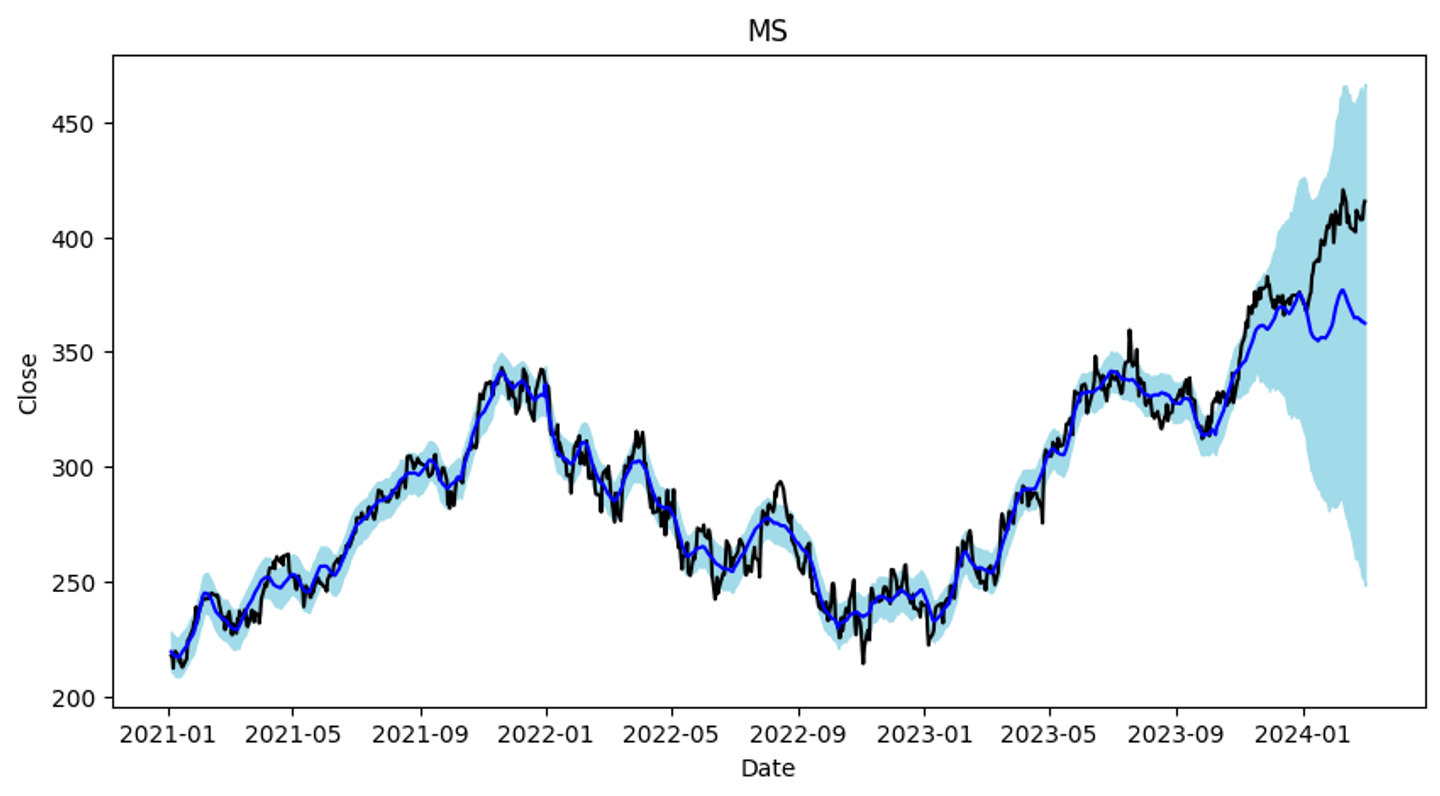
-> 학습 기간 이후 주식반등을 예측함
# 성능평가를 위한 전처리
forecast_amazon2['Date'] = forecast_amazon2['ds']
# 테스트를 위한 start='2021-01-01', end='2024-03-04'의 데이터
amazon = yf.download('AMZN', start='2021-01-01', end='2024-03-04').reset_index()
test_set_amazon2 = pd.merge(amazon, forecast_amazon2, how='inner', on='Date')
#테스트 데이터셋 검증
# MSE가 0이라면 예측 모델은 완벽하게 실제값을 예측하는 것이며, MSE가 크다면 예측 오차가 크다는 것을 의미
from sklearn.metrics import mean_squared_error
mse_test_amazon2 = mean_squared_error(test_set_amazon2['Close'], test_set_amazon2['yhat'])
mse_test_amazon2>>> 결과 : 37.67348398062116
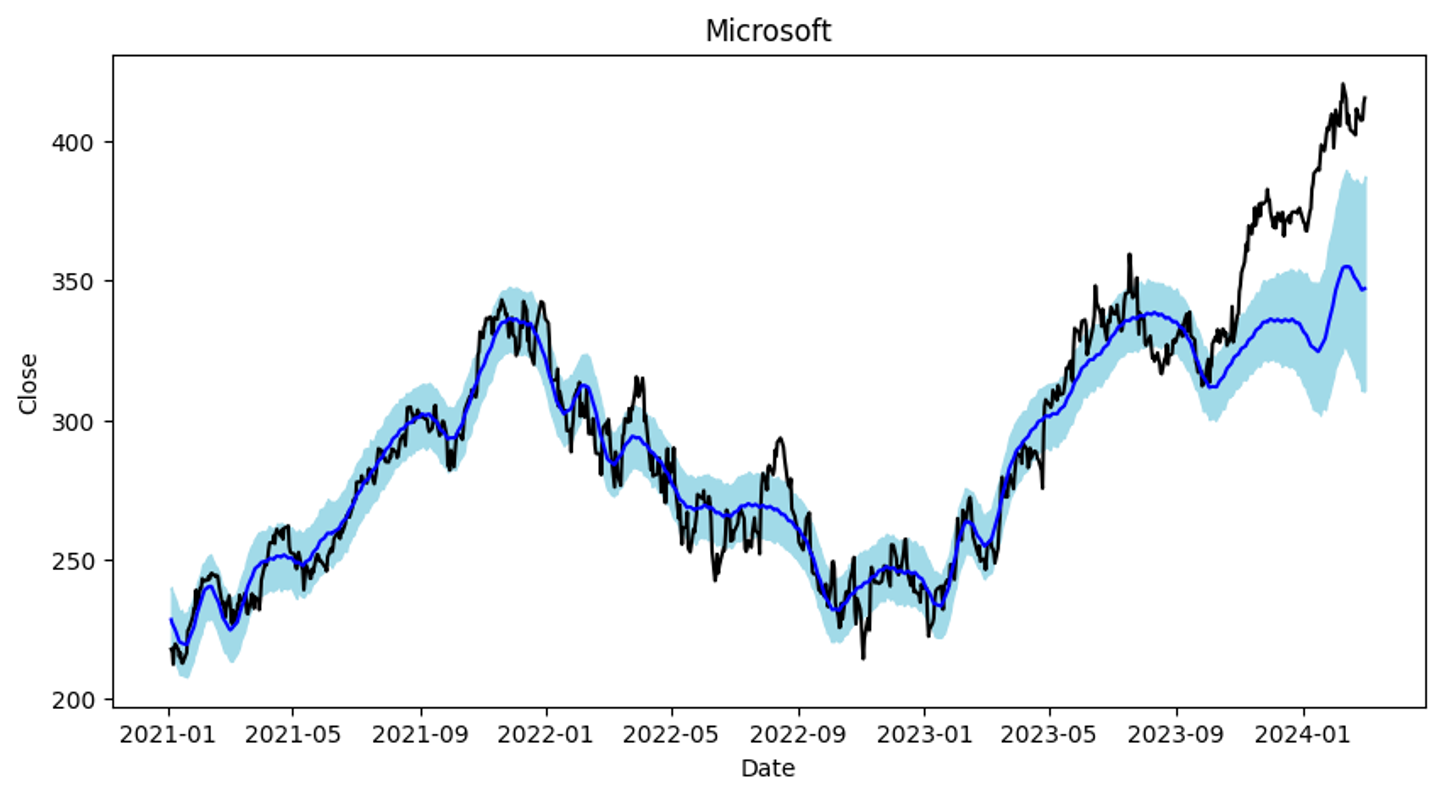
MICROSOFT 모델링하기
학습데이터 start = 2021-01-01 end = 2023-09-30(하락추세)
테스트데이터 start=2021-01-01 end=2024-03-
모델링
아마존의 seasonality_mode 반영
# 매개변수 조정
model_ms2= Prophet(
# trend -> 높을수록 디테일하게 확인, 0.05~0.01 사이가 좋은 듯
changepoint_prior_scale=0.03,
# seasonality는 작아질 수록 커짐
yearly_seasonality = 20,
# 토,일에 거래가 없는 요일 반영
weekly_seasonality = 15,
daily_seasonality = True,
seasonality_prior_scale = 0, #10이상일경우 오차가 커짐
seasonality_mode = 'multiplicative')
# ms는 'additive'보다 multiplicative 더 최적 -> 오차가 더 작아짐, 연도별 잔폭이 더 커지는 듯
# 미국의 휴일 설정
model_ms2.add_country_holidays(country_name='US')
#model_ms2.add_seasonality(name='monthly', period=30.5, fourier_order=5)
# 학습
model_ms2.fit(df_ms)
future_ms2 = model_ms2.make_future_dataframe(periods = fcast_time, freq = 'D')
forecast_ms2= model_ms2.predict(future_ms2)
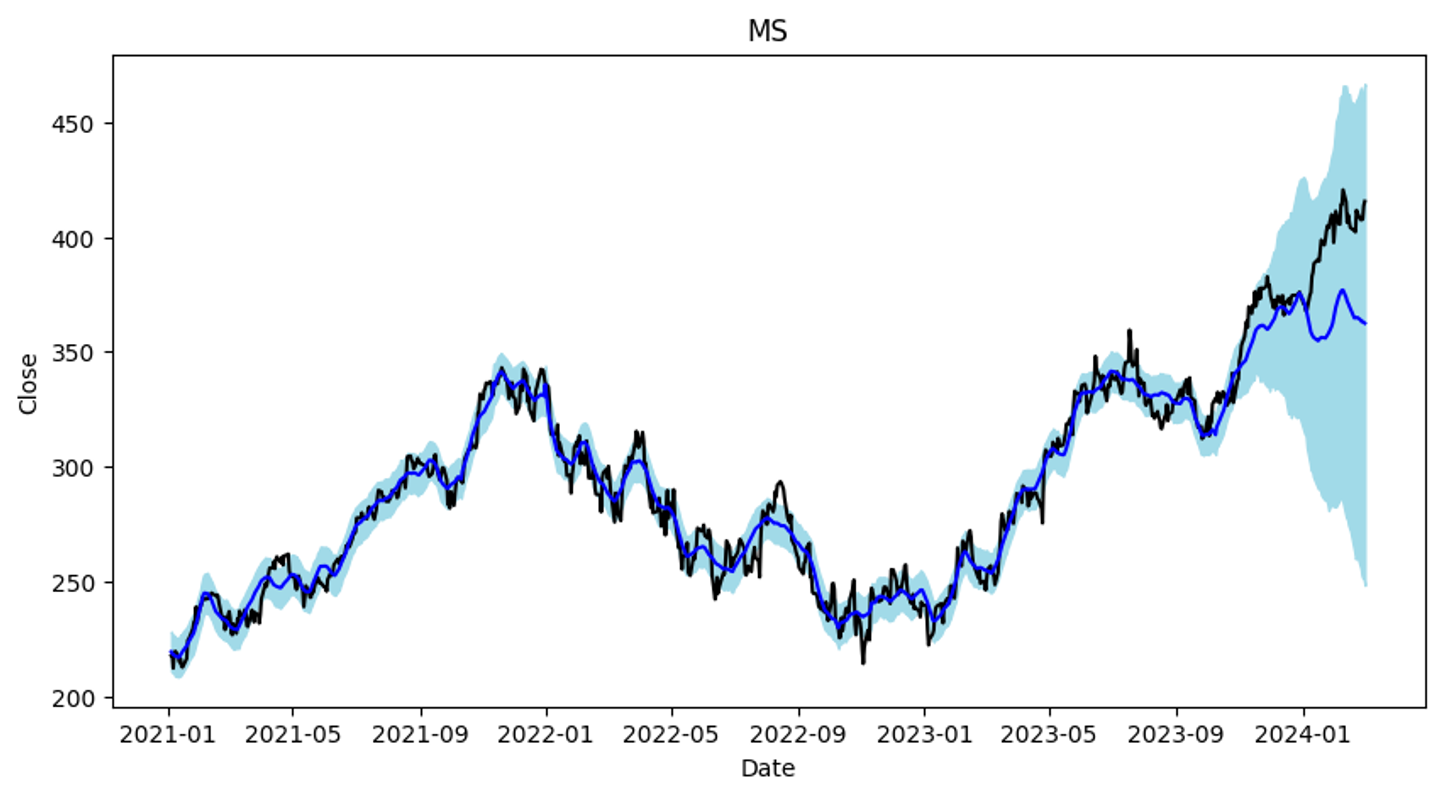
성능평가
# 성능평가를 위한 전처리 -> 조정값
forecast_ms2['Date'] = forecast_ms2['ds']
# 테스트를 위한 start='2021-01-01', end='2024-03-04'의 데이터
ms = yf.download('MSFT', start='2021-01-01', end='2024-03-04').reset_index()
test_set_ms2 = pd.merge(ms, forecast_ms2, how='inner', on='Date')
#테스트 데이터셋 검증
# MSE가 0이라면 예측 모델은 완벽하게 실제값을 예측하는 것이며, MSE가 크다면 예측 오차가 크다는 것을 의미
mse_test_ms2 = mean_squared_error(test_set_ms2['Close'], test_set_ms2['yhat'])
mse_test_ms2>>> 120.85915161177347
'프로젝트' 카테고리의 다른 글
| [분석프로젝트] 장난감 자동차 회사의 RFM 고객세그먼트 (0) | 2024.03.28 |
|---|---|
| 프로젝트 주제 사례 (0) | 2024.03.18 |
| [주식 프로젝트2] 주식데이터를 통해 기획하기 (0) | 2024.03.13 |
| [주식 프로젝트1] 야후 파이낸스 살펴보기 (1) | 2024.02.29 |
| [분석프로젝트] 웹 페이지 개선을 통한 A/B테스트: t-test, 시각화 (0) | 2024.02.28 |



